Bài 5: Database
Bài 5: Database

Kiến thức nền tảng để học Cloud
Part 5 of 5
Table of Contents
- 1. Triển khai MySQL DB single
- 2. Bật slow query log của MySQL, MariaDB
- 3. Sử dụng hedisql để truy cập vào MySQL
- 4. Triển khai MySQL DB Cluster (galera)
- 5. Triển khai SQL Server single
- 6. Triển khai SQL Server Always-on Cluster
- 7. Triển khai Redis single
- 8. Triển khai Redis Cluster
- 9. MySQL Active - Standby (Active/Passive)
1. Triển khai MySQL DB single
1.1. Trên Ubuntu
- Cài đặt MariaDB từ APT
sudo apt update
sudo apt install mariadb-server -y
- Thiết lập ban đầu
sudo mysql_secure_installation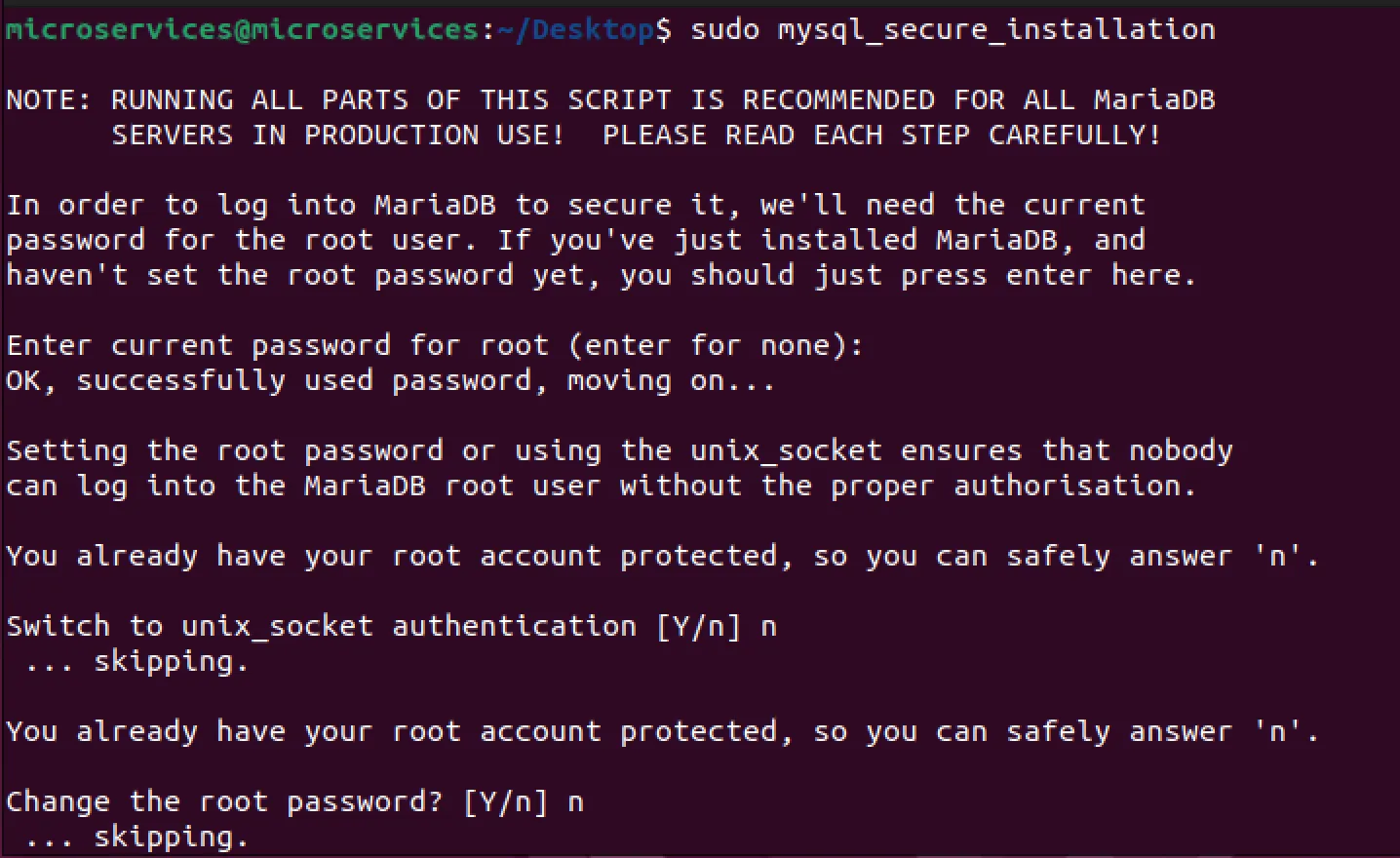
- Tạo User kietna với quyền Root
sudo mariadb
GRANT ALL ON *.* TO 'kietna'@'localhost' IDENTIFIED BY '123456@abc' WITH GRANT OPTION;
FLUSH PRIVILEGES;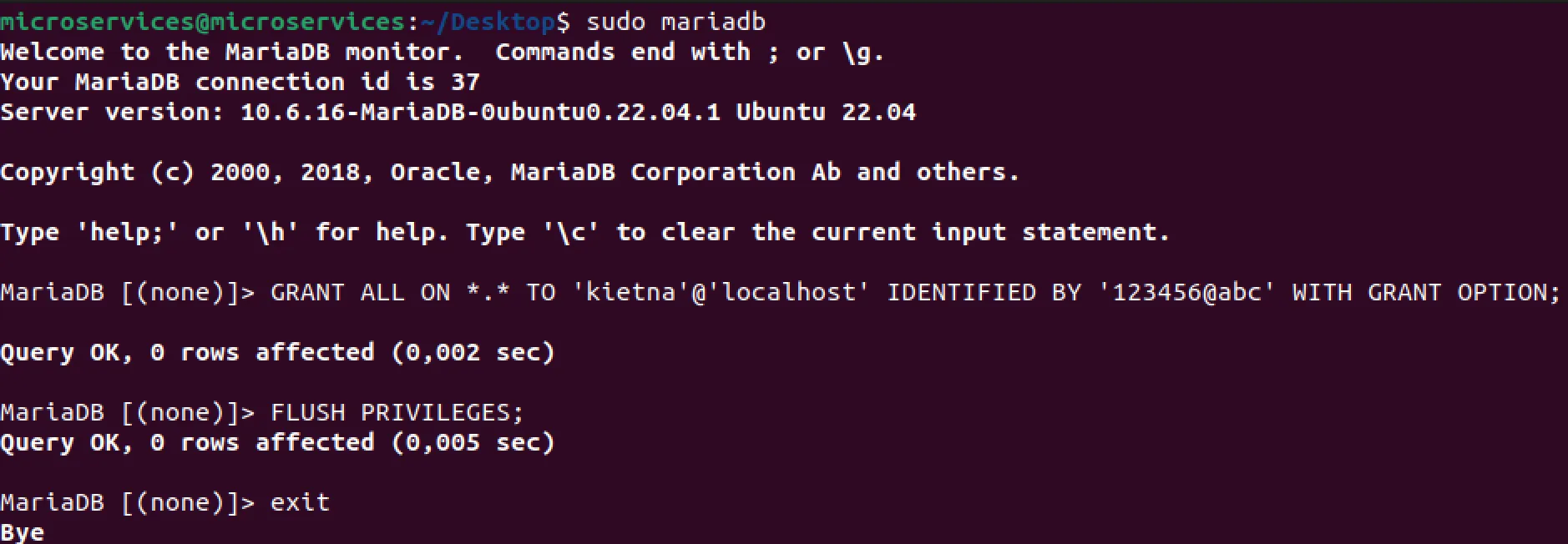
1.2. Trên Windows
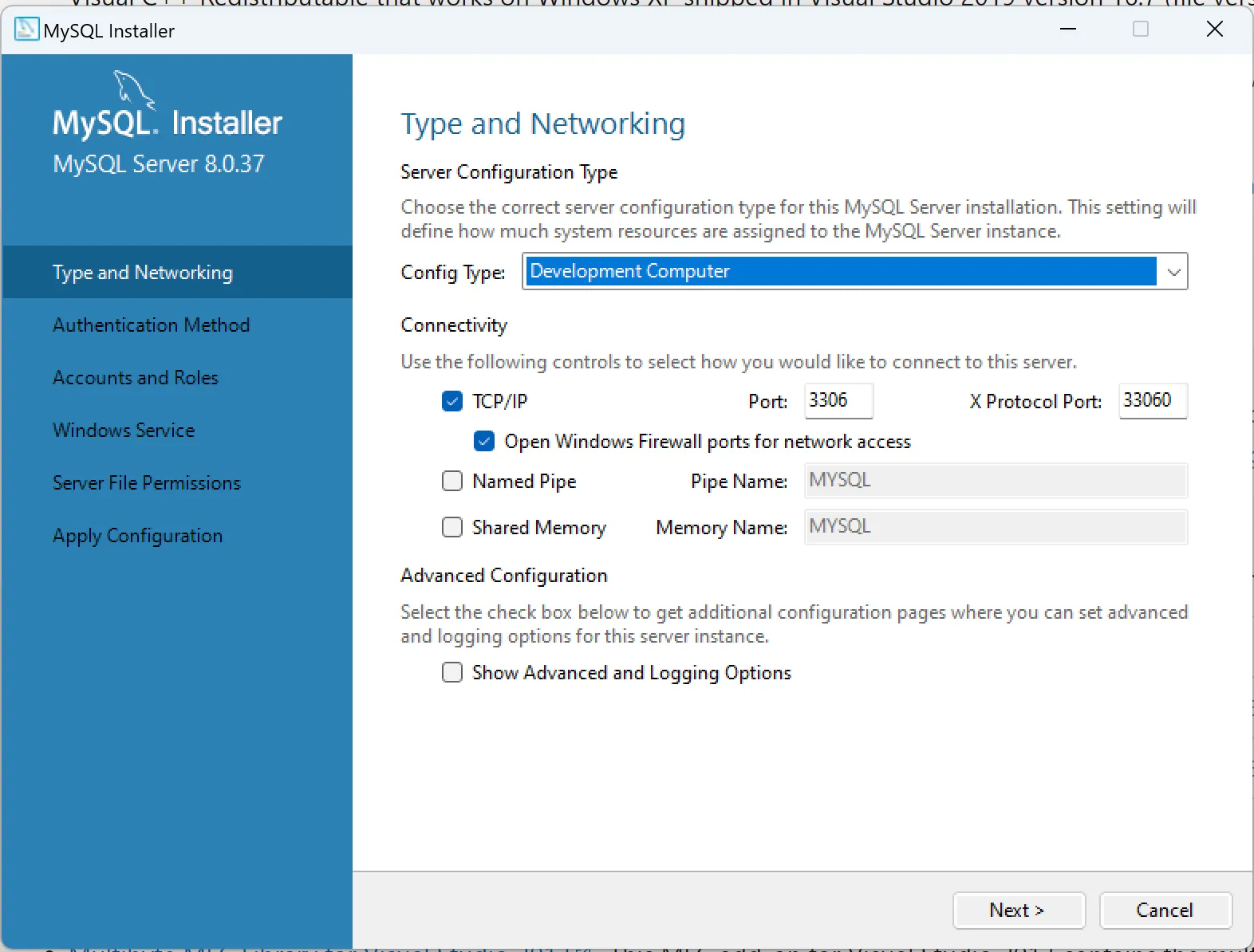
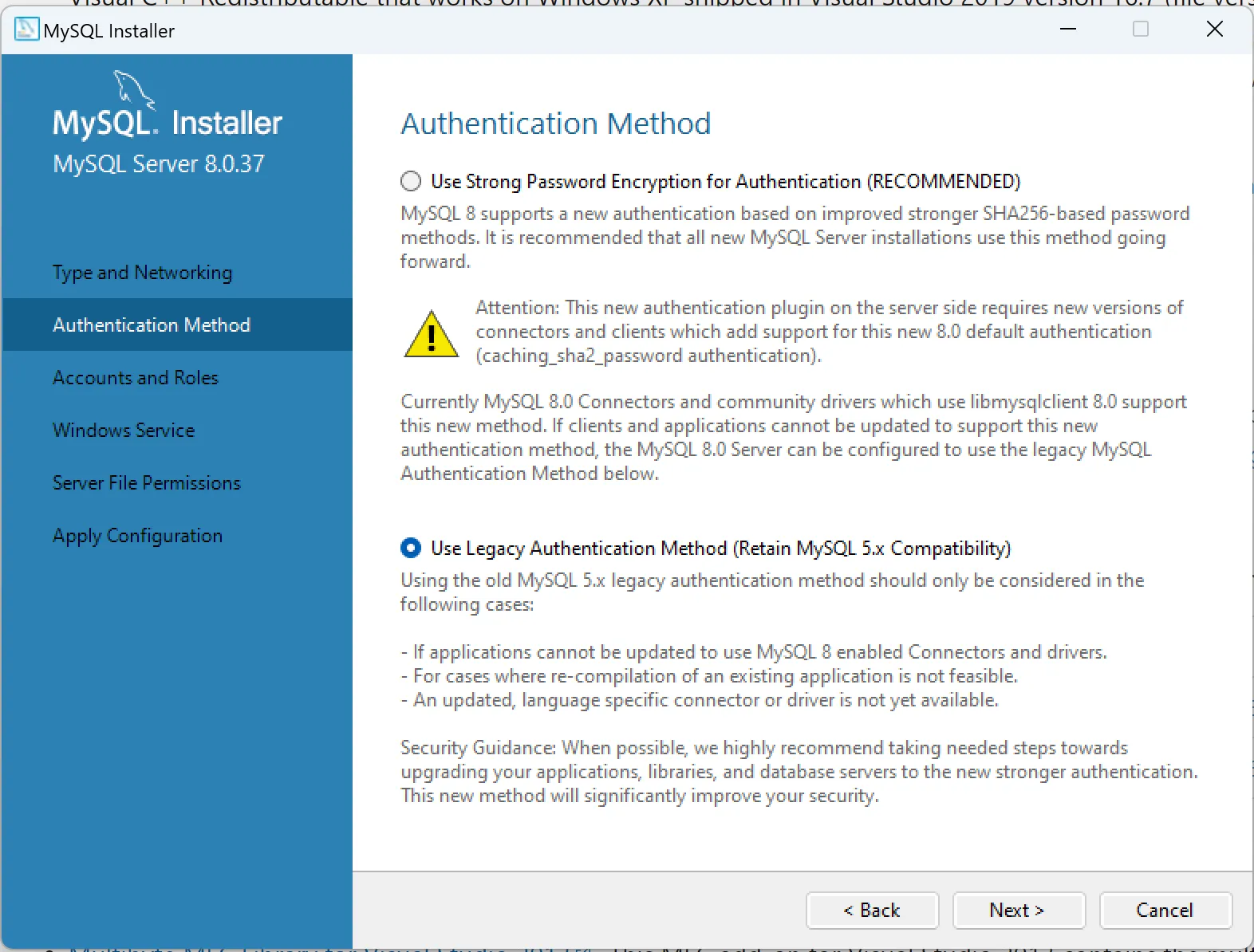
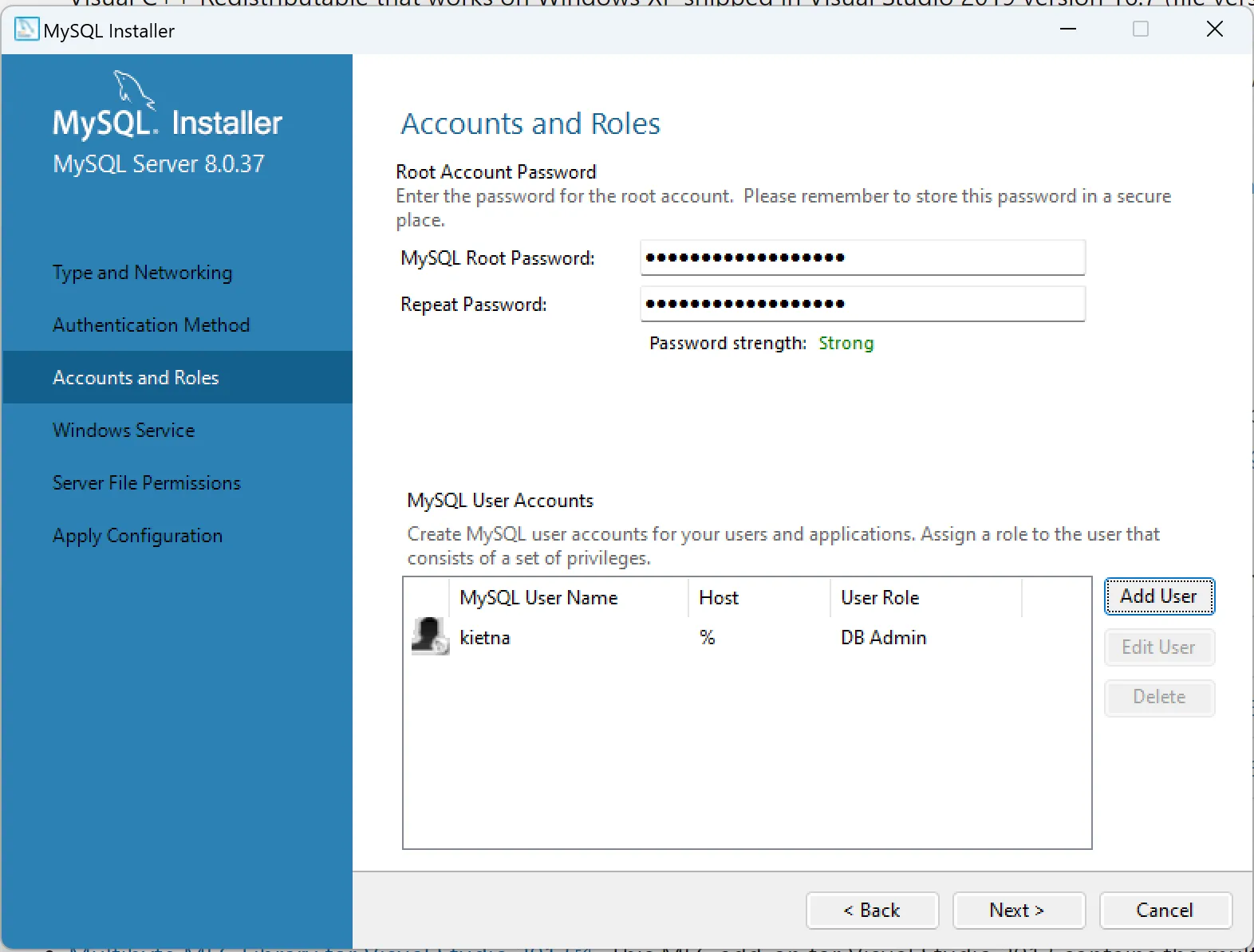
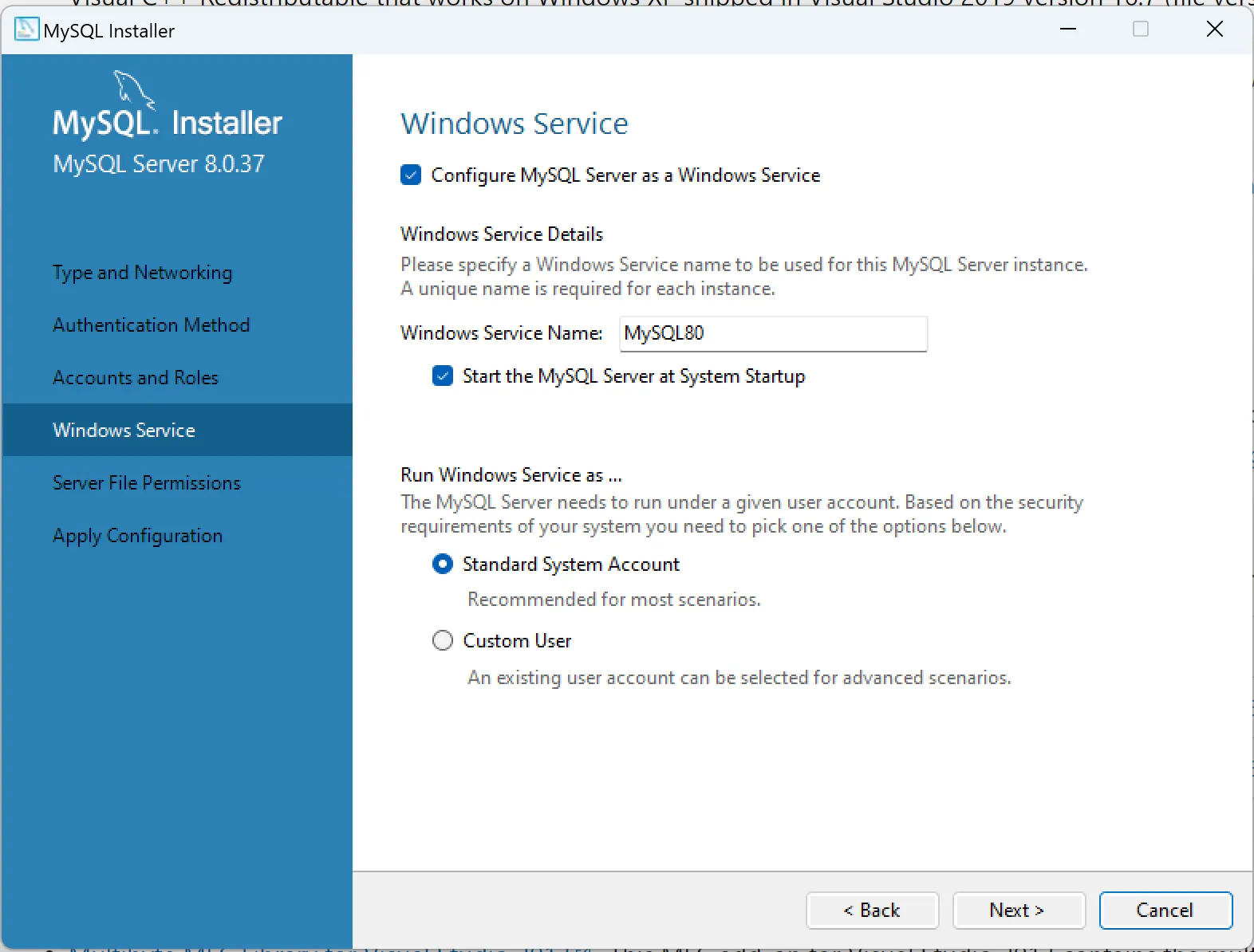
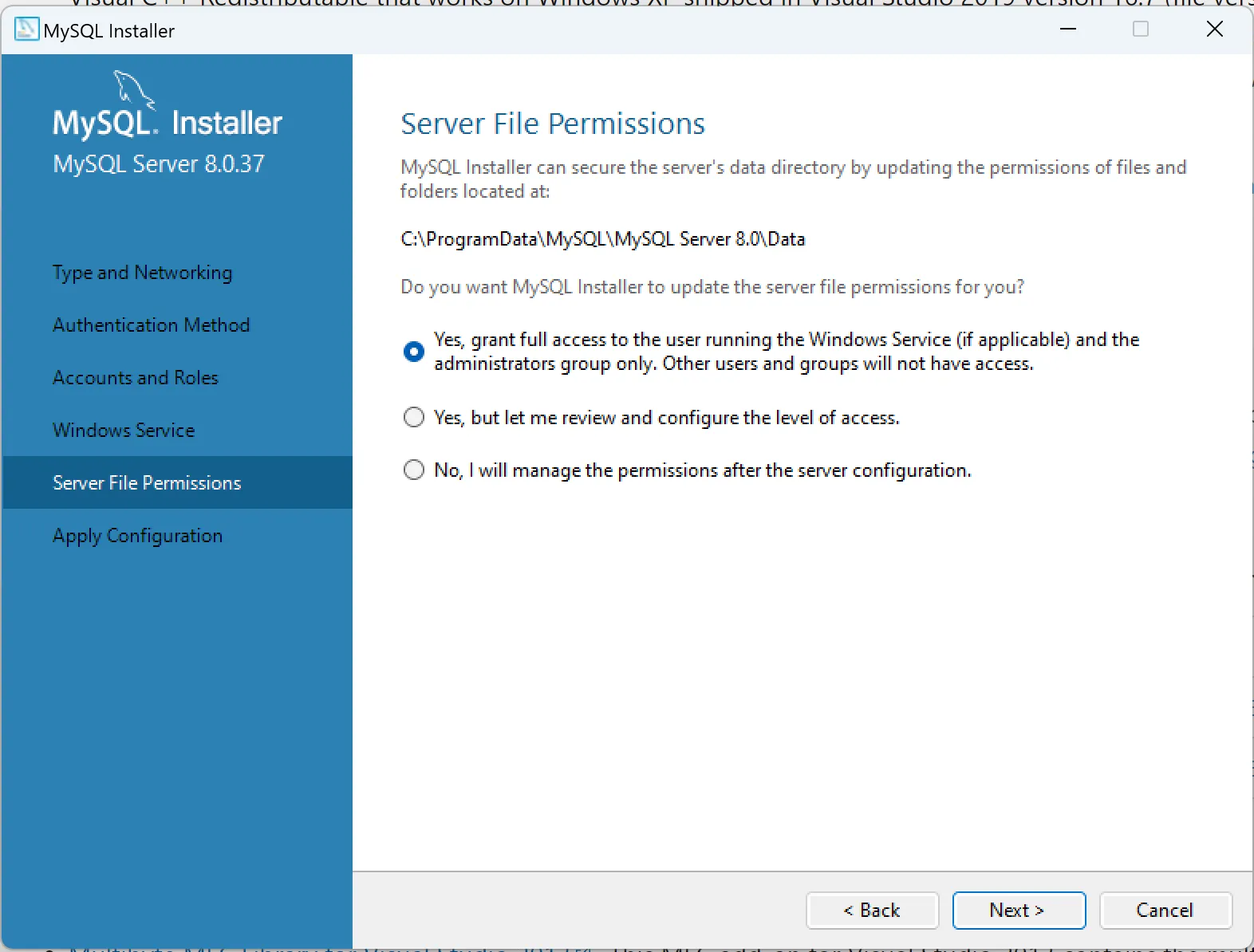
2. Bật slow query log của MySQL, MariaDB
sudo nano /etc/mysql/my.cnf
slow_query_log
slow_query_log_file=/var/lib/mysql/slow.log
long_query_time=4.0
sudo systemctl restart mariadb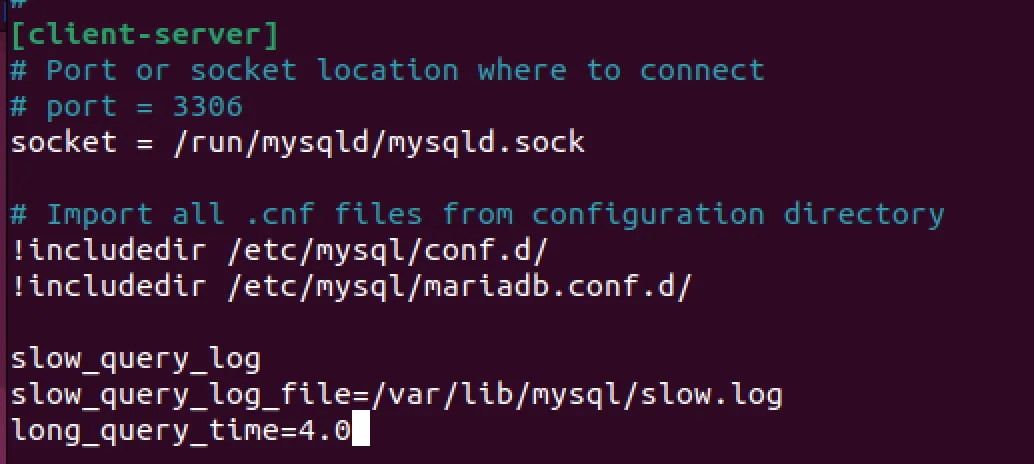
3. Sử dụng hedisql để truy cập vào MySQL
- Tải về HediSQL https://www.heidisql.com/download.php
- Tạo một Session mới
- Điền các thông tin của máy chủ
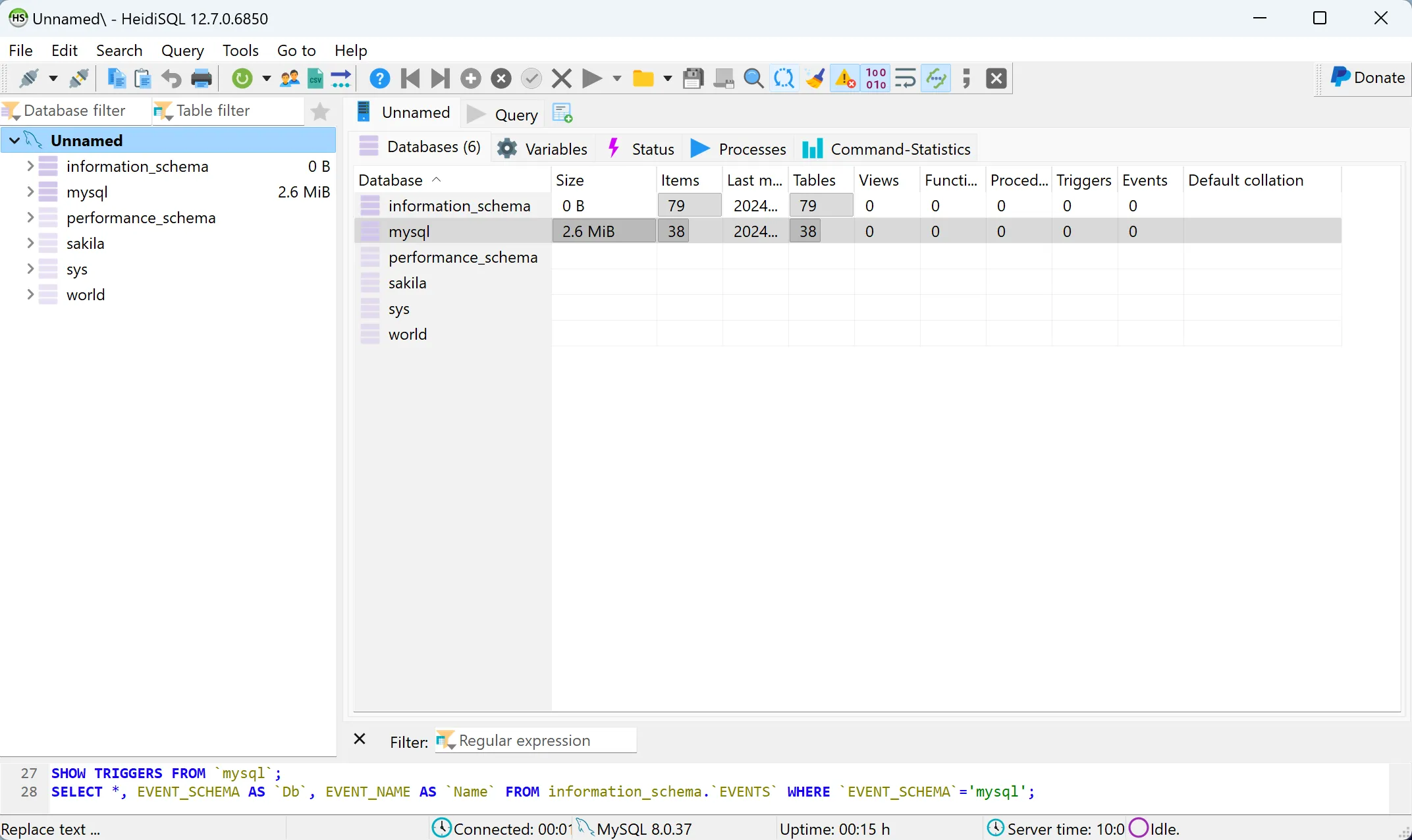
- Kết nối thành công
4. Triển khai MySQL DB Cluster (galera)
4.1. Lab triển khai Galera
- Chuẩn bị 3 máy AlmaLinux 9 với các thông tin như sau
- master1: 192.168.10.11
- worker1: 192.168.10.12
- worker2: 192.168.10.13
- Tiến hành cài đặt MariaDB lên cả 3 máy
vi /etc/yum.repos.d/mariadb.repo
# MariaDB 10.11 RedHatEnterpriseLinux repository list - created 2023-10-30 14:19 UTC
# https://mariadb.org/download/
[mariadb]
name = MariaDB
# rpm.mariadb.org is a dynamic mirror if your preferred mirror goes offline. See https://mariadb.org/mirrorbits/ for details.
# baseurl = https://rpm.mariadb.org/10.11/rhel/$releasever/$basearch
baseurl = https://mirror.23m.com/mariadb/yum/10.11/rhel/$releasever/$basearch
module_hotfixes = 1
# gpgkey = https://rpm.mariadb.org/RPM-GPG-KEY-MariaDB
gpgkey = https://mirror.23m.com/mariadb/yum/RPM-GPG-KEY-MariaDB
gpgcheck = 1
yum install MariaDB-server MariaDB-client -y
sudo systemctl enable mariadb
sudo systemctl start mariadb
sudo systemctl status mariadb- Tiến hành thiết lập ban đầu cho MariaDB
mysql
ALTER USER 'root'@'localhost' IDENTIFIED BY '123456@abc';
DELETE FROM mysql.user WHERE User='';
DELETE FROM mysql.user WHERE User='root' AND Host NOT IN ('localhost', '127.0.0.1', '::1');
DROP DATABASE IF EXISTS test;
FLUSH PRIVILEGES;
EXIT;- Tạo file cấu hình Galera
sudo vi /etc/my.cnf.d/galera.cnf- Trên máy Master
[mysqld]
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="test_cluster"
wsrep_cluster_address="gcomm://192.168.10.11,192.168.10.12,192.168.10.13"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="192.168.10.11"
wsrep_node_name="master1"- Trên máy Worker1
[mysqld]
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="test_cluster"
wsrep_cluster_address="gcomm://192.168.10.11,192.168.10.12,192.168.10.13"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="192.168.10.12"
wsrep_node_name="worker1"- Trên máy Worker2
[mysqld]
binlog_format=ROW
default-storage-engine=innodb
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
# Galera Provider Configuration
wsrep_on=ON
wsrep_provider=/usr/lib64/galera-4/libgalera_smm.so
# Galera Cluster Configuration
wsrep_cluster_name="test_cluster"
wsrep_cluster_address="gcomm://192.168.10.11,192.168.10.12,192.168.10.13"
# Galera Synchronization Configuration
wsrep_sst_method=rsync
# Galera Node Configuration
wsrep_node_address="192.168.10.13"
wsrep_node_name="worker2"- Tạm dừng MariaDB ở cả 3 Node
sudo systemctl stop mariadb- Khởi tạo Cluster trên máy Master
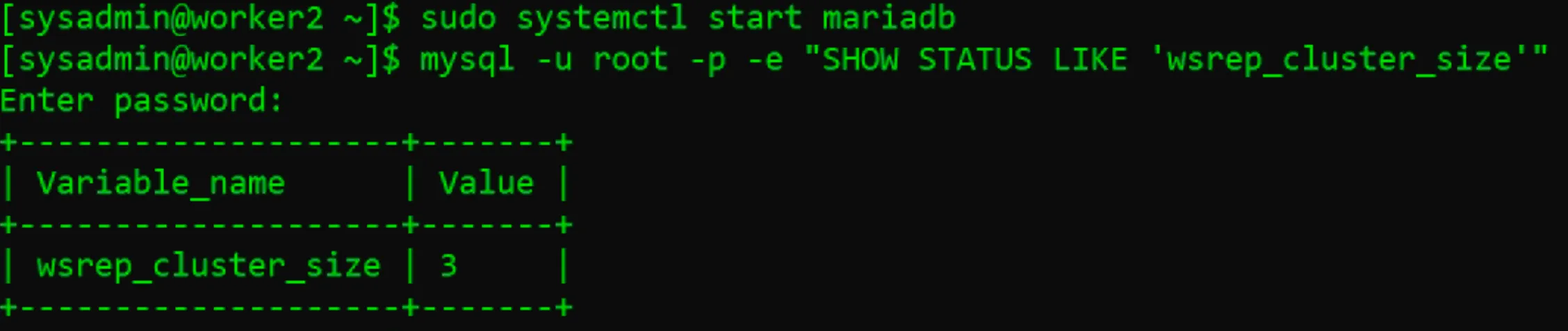
sudo galera_new_cluster- Kiểm tra ClusterSize thấy có 1 máy trong Node
mysql -u root -p -e "SHOW STATUS LIKE 'wsrep_cluster_size'"
- Khởi động MariaDB ở máy Worker1, kiểm tra lại ClusterSize

- Khởi động MariaDB ở máy Worker2, kiểm tra ClusterSize
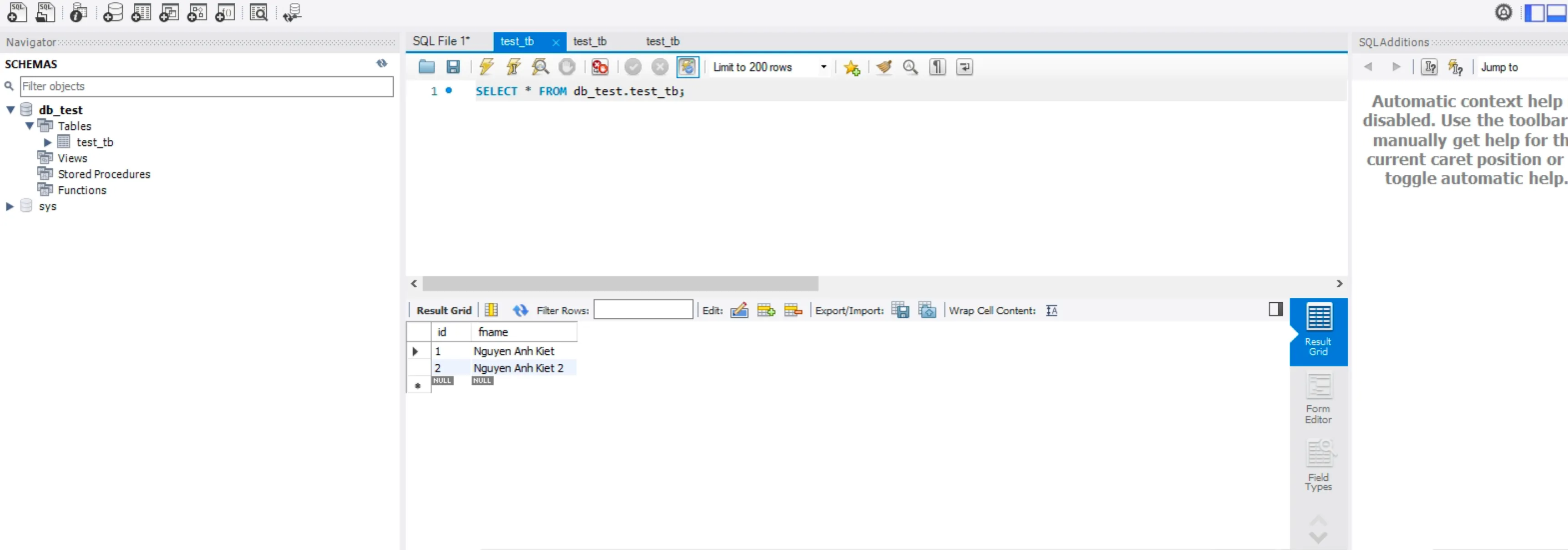
- Tiến hành tạo bảng & chèn 1 dữ liệu vào bảng

- Tại máy Worker1, tiến hành đọc thông tin từ bảng & chèn 1 dữ liệu mới

- Thực hiện tương tự với Worker2
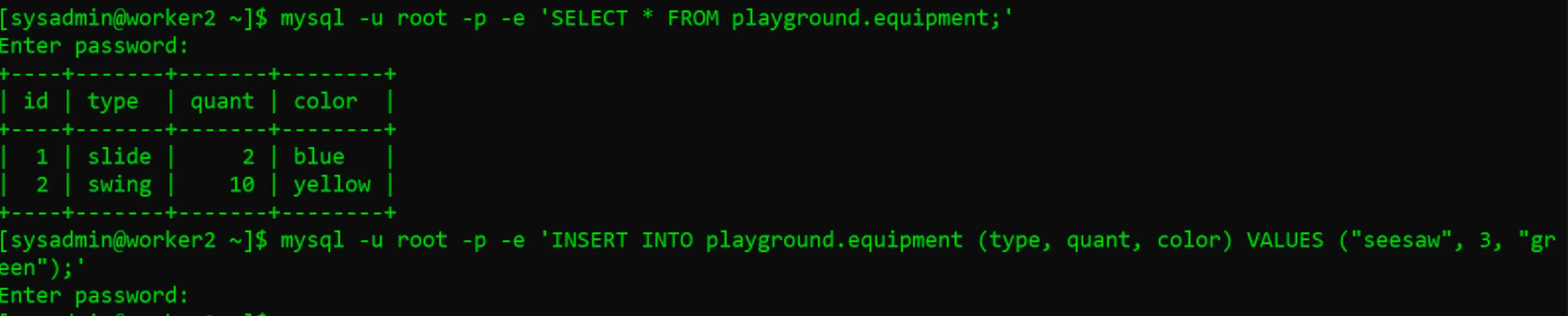
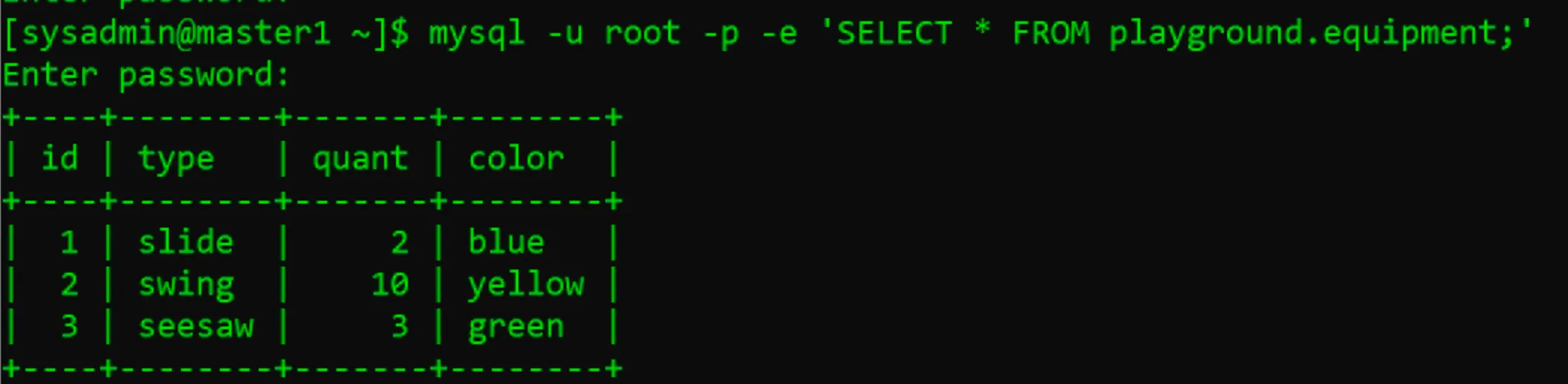
- Thực hiện đọc thông tin ở máy Master1
4.2. Vấn đề khởi động lại Cluster
- Khi tất cả các node bị tắt tại một thời điểm, thì cluster cũng bị ngưng theo
- Dữ liệu cluster vẫn còn, nhưng cluster không còn tồn tại nữa.
- Bạn cần phải khởi tạo lại cluster
- Nếu cluster chưa được khởi tạo mà mariadb ở node đầu tiên có thể khởi động bình thường
- Node đầu tiên này sẽ cố gắng kết nối tới ít nhất một trong các nodes ở trong danh sách wsrep_cluster_address.
- Nếu không có nodes nào đang chạy, quá trình này sẽ thất bại
- Khởi tạo node đầu tiên sẽ giúp giải quyết được vấn đề này
4.2.1. Các định Node “Cao cấp”
- Trong một vài trường hợp Galera sẽ từ chối khởi tạo một node nếu node đó không phải node “cao cấp” nhất trong cluster.
- Galera đưa ra kiểu xác định này nếu node đó không phải node cuối cùng bị tắt trong cluster. Trong một vài trường hợp, cần phải can thiệp thủ công
- Chỉnh sửa safe_to_bootstrap=1 ở file grastate.dat nằm trong thư mục datadir ở node cao cấp nhất
- Bạn có thể xác định node nào là cao cấp nhất bằng cách kiểm tra file grastate.dat ở mỗi node và tìm kiếm node nào có giá trị seqno cao nhất
- Trong trường hợp hệ chống bị lỗi và seqno = -1 thì bạn có thể tìm ra node cao cấp nhất bằng cách khôi phục giá trị seqno ở mỗi node bằng câu lệnh sau
mariadbd --wsrep_recover4.2.2. Systemd và Galera Recovery
- Ở các hệ điều hành sử dụng systemd, vị trí mỗi node có thể được phục hồi bằng cách chạy script
galera_recovery- Nếu bạn sử dụng systemd có hỗ trợ phương thức tương tác với nhiều tiến trình MariaDB, bạn có thể phục hồi vị trí của một tiến trình cụ thể bằng cách sử dụng tên của chúng như một hậu tố
galera_recovery mariadb@node1- Script galera_recovery khôi phục vị trí một node bằng cách chạy mariadbd với option wsrep_recover
- Khi galera_recovery chạy mariadbd, nó không ghi vào error log. Thay vào đó nó chuyển hướng mariadbd log tới một file với định dạng /tmp/wsrep_recovery.XXXXXX với XXXXXX là chuỗi ngẫu nhiên
- Khi Galera được kích hoạt, MariaDB systemd service tự động chạy galera_recovery script để khởi chạy MariaDB, do đó MariaDB chạy với vị trí Galera đúng.
4.2.3. Galera Recovery
- Sau khi khởi động lên, thực thi câu lệnh sau tại các node để kiểm tra
sudo cat /var/lib/mysql/grastate.dat- Tại máy Master1
[sysadmin@master1 ~]$ sudo cat /var/lib/mysql/grastate.dat
# GALERA saved state
version: 2.1
uuid: b0a50f16-1417-11ef-879b-5b16f64627f8
seqno: -1
safe_to_bootstrap: 0- Tại máy Worker1
[sysadmin@worker1 ~]$ sudo cat /var/lib/mysql/grastate.dat
# GALERA saved state
version: 2.1
uuid: b0a50f16-1417-11ef-879b-5b16f64627f8
seqno: -1
safe_to_bootstrap: 0- Tại máy Worker2
[sysadmin@worker2 ~]$ sudo cat /var/lib/mysql/grastate.dat
# GALERA saved state
version: 2.1
uuid: b0a50f16-1417-11ef-879b-5b16f64627f8
seqno: 10
safe_to_bootstrap: 1- Dễ thấy máy Worker2 có trạng thái safe_to_bootstrap: 1 do đó chúng ta khởi tạo lại Cluster từ máy 2
sudo galera_new_cluster- Lần lượt bật MariaDB trên các máy còn lại là được
- Trong trường hợp không có node nào safe_to_bootstrap ta cần xác định vị trí các node bằng câu lệnh
sudo -u mysql mysqld --wsrep-recover- Ta sẽ thu được output dạng (Trong đó 31 là postion của node)
2019-08-05 18:53:55 0 [Note] WSREP: Recovered position: d89c79f4-b308-11e9-9931-8f96b3cc57b2:31- Tại Node có Position lớn nhất, ta chạy lệnh sau và tiến hành Bootstrap trên Node đó
sed -i 's/safe_to_bootstrap: 0/safe_to_bootstrap: 1/' /var/lib/mysql/grastate.dat
5. Triển khai SQL Server single
- Download SQL Server: https://www.microsoft.com/en-us/sql-server/sql-server-downloads
- Chọn Custom
- Chọn Install
- Installation ⇒ New SQL Server Installation

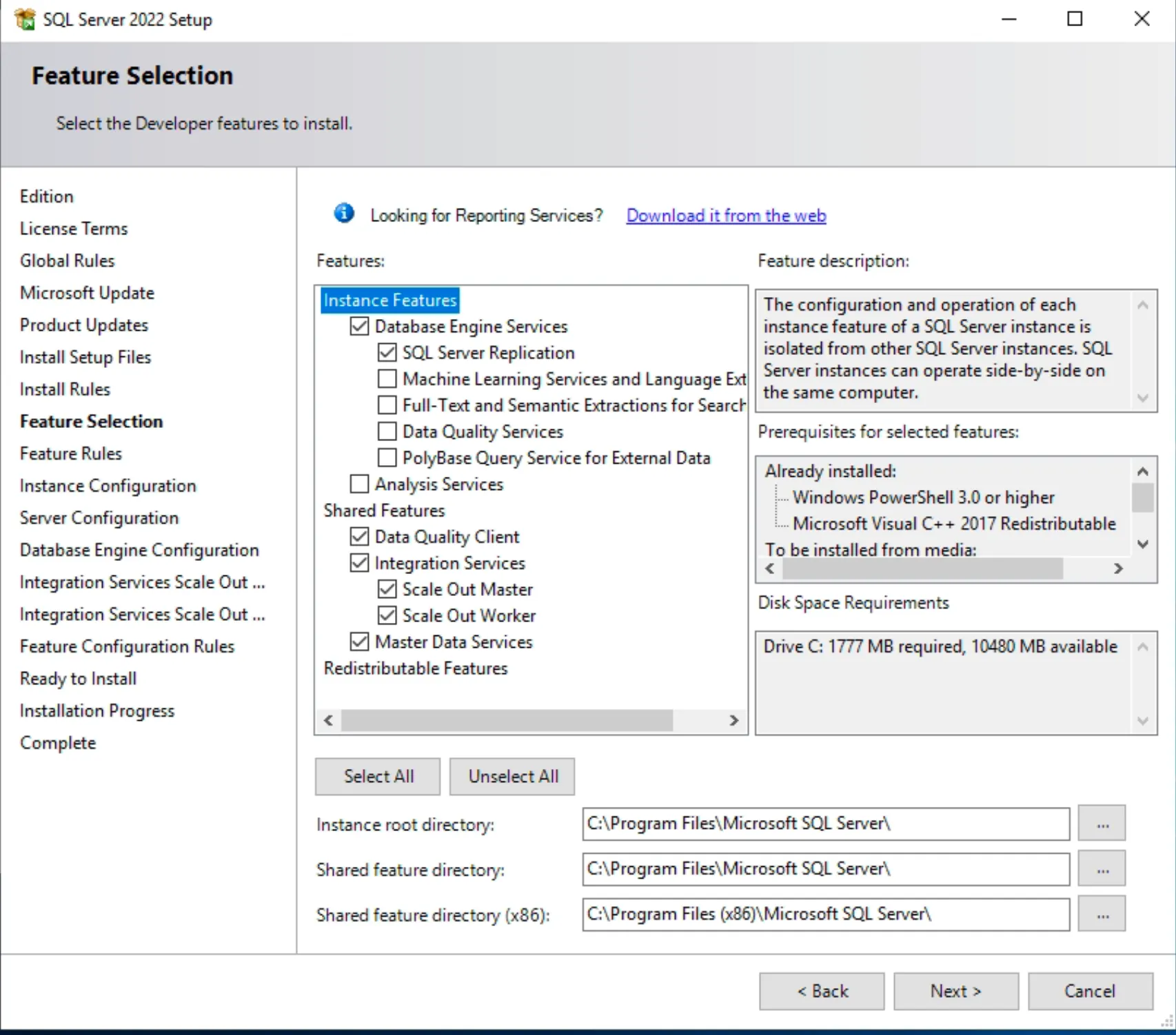
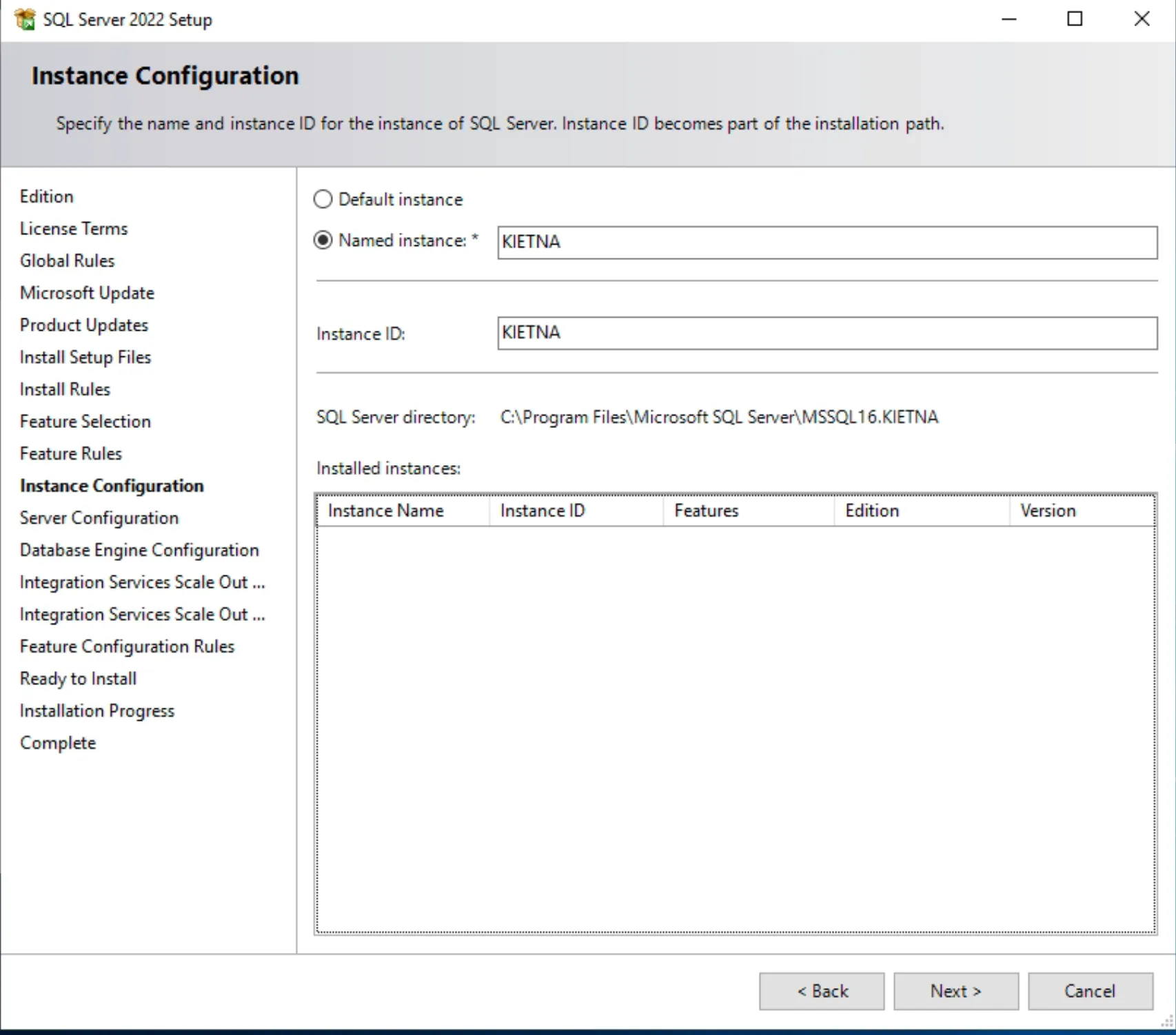
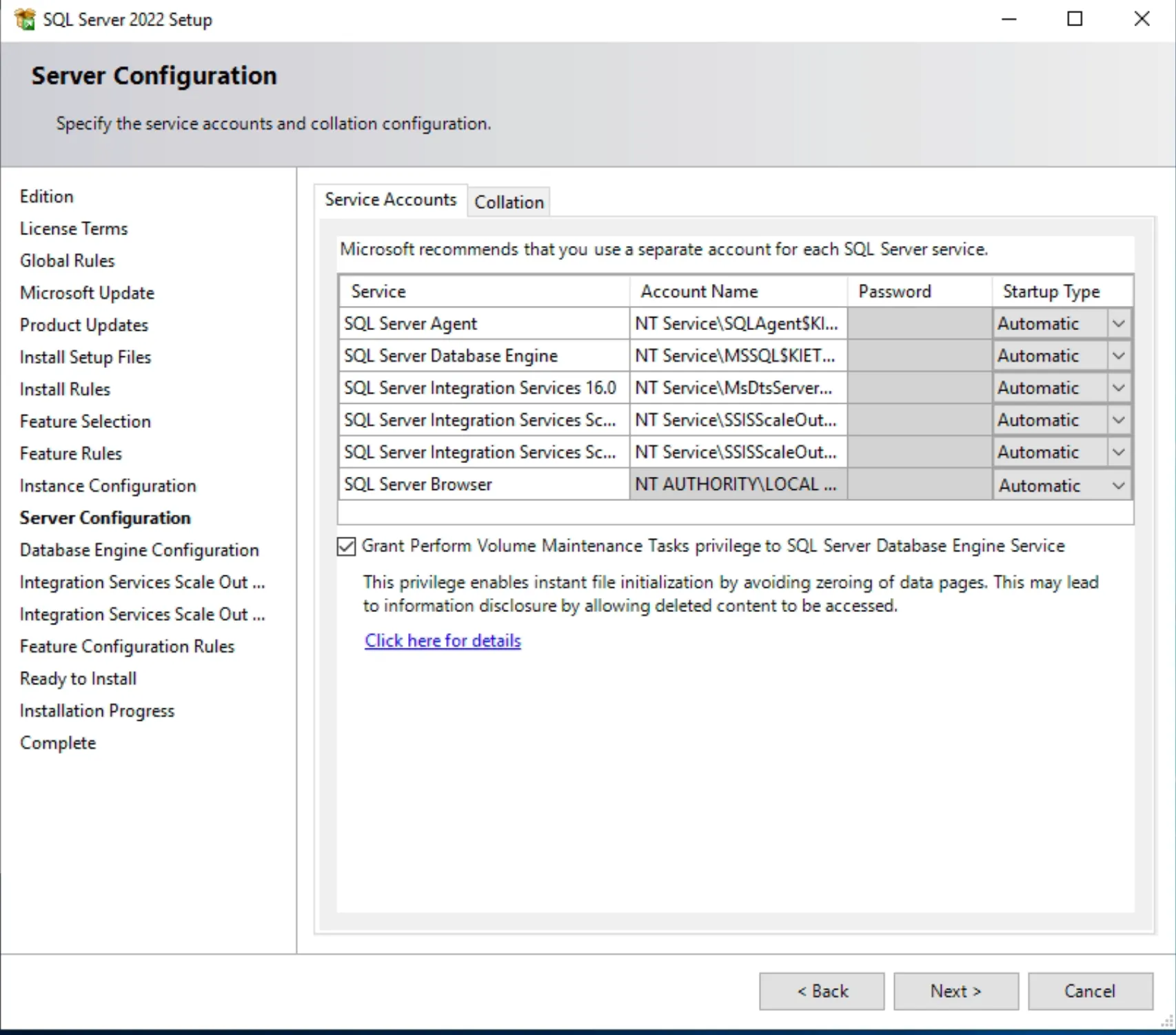
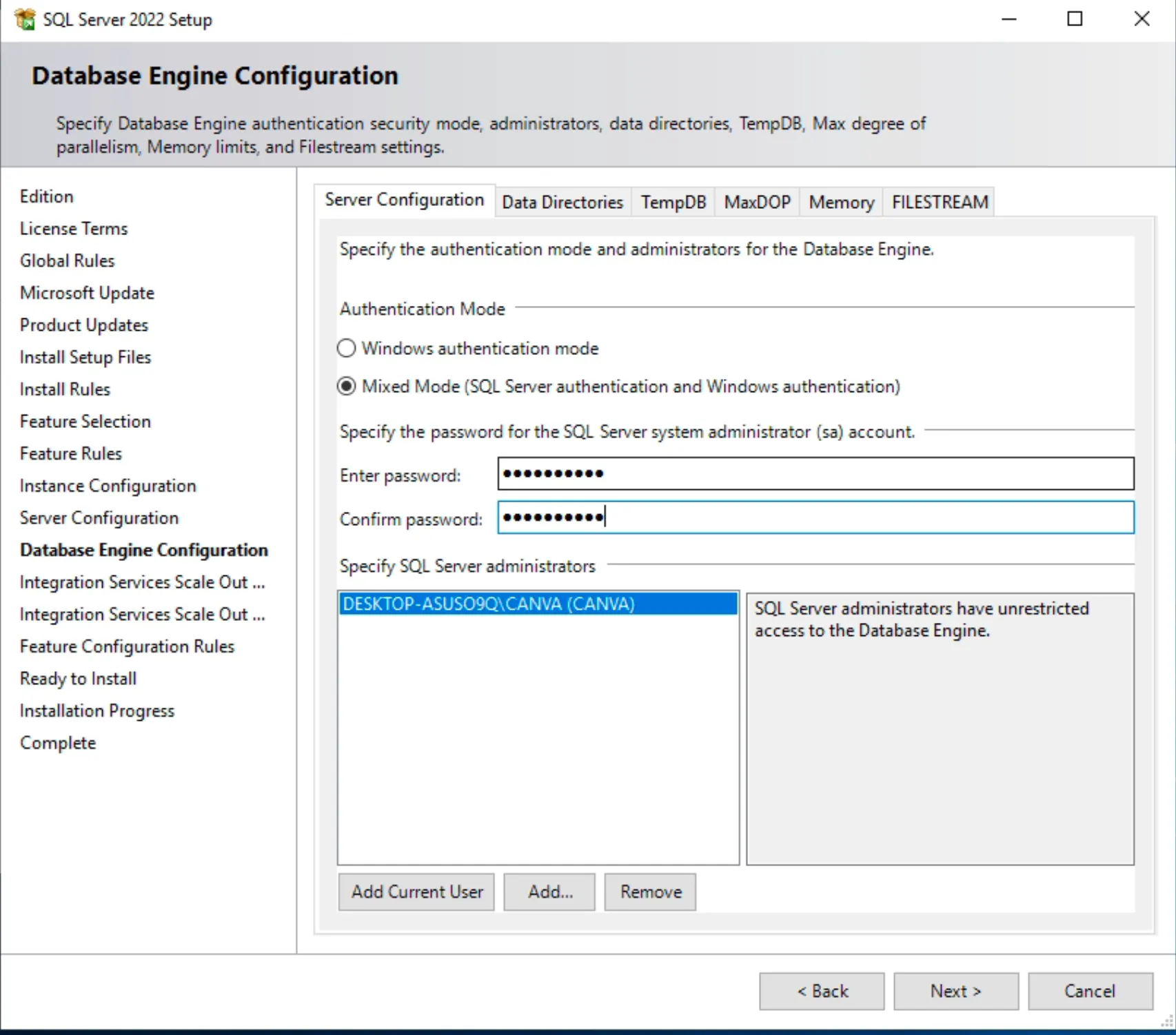
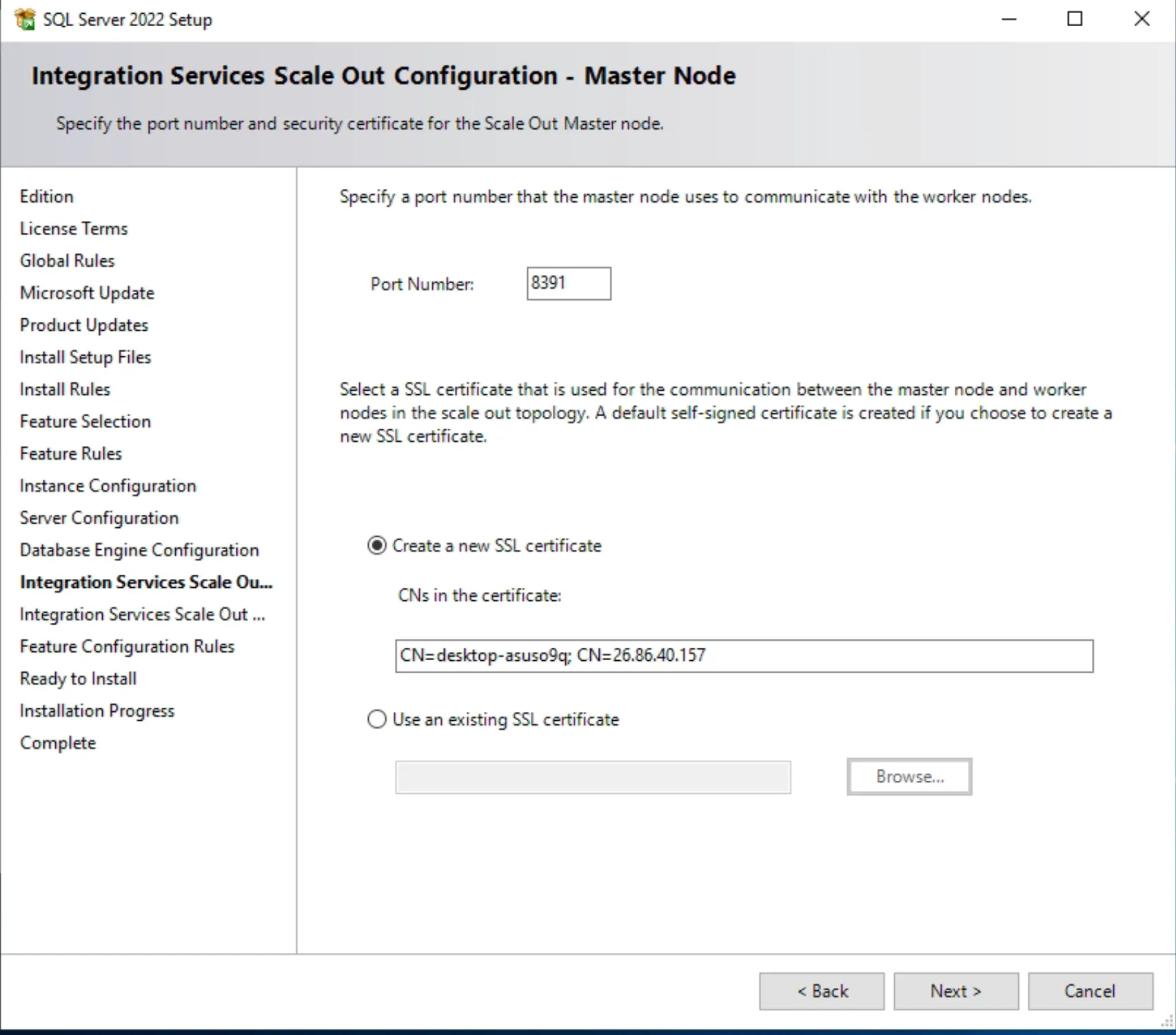
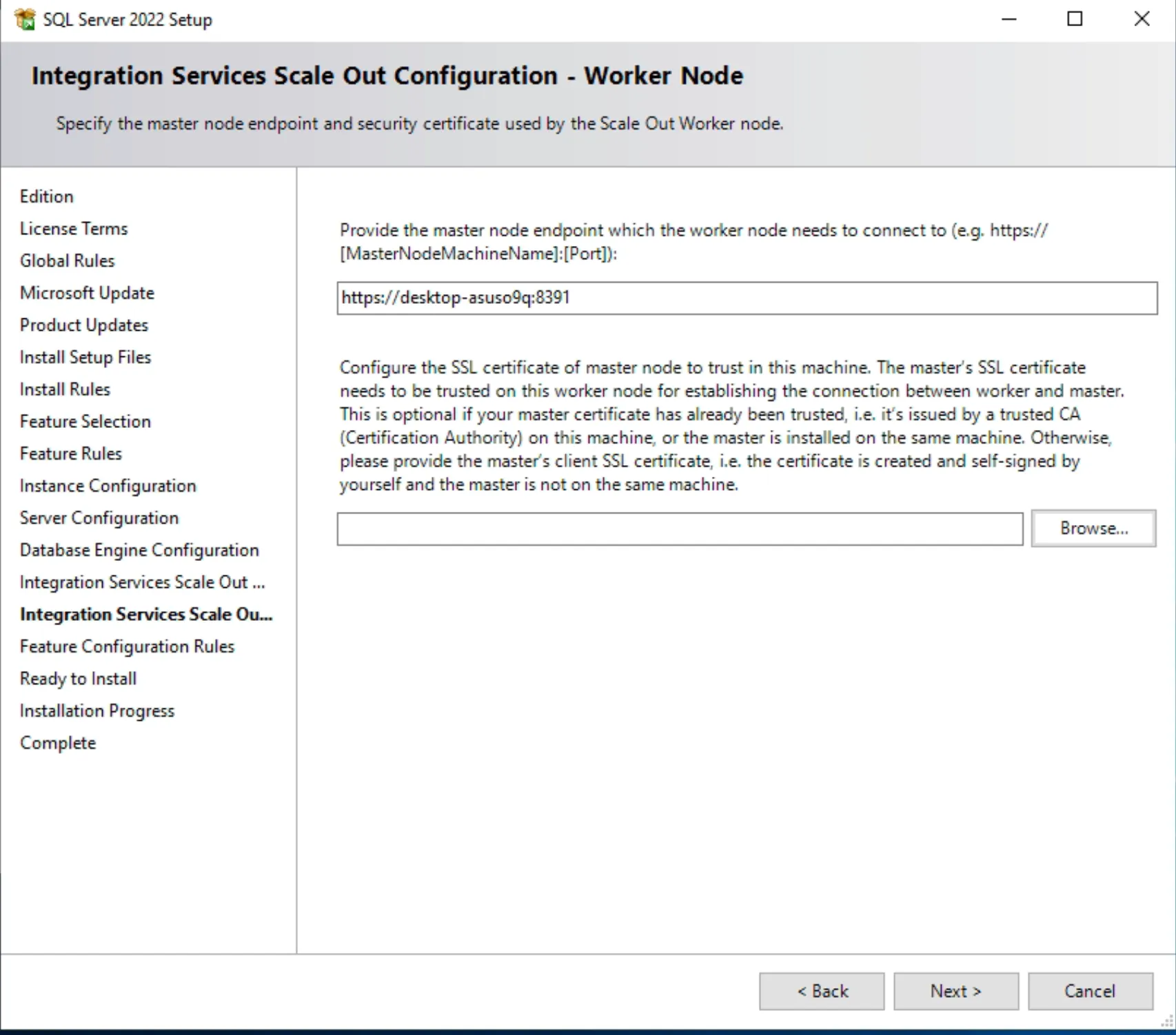
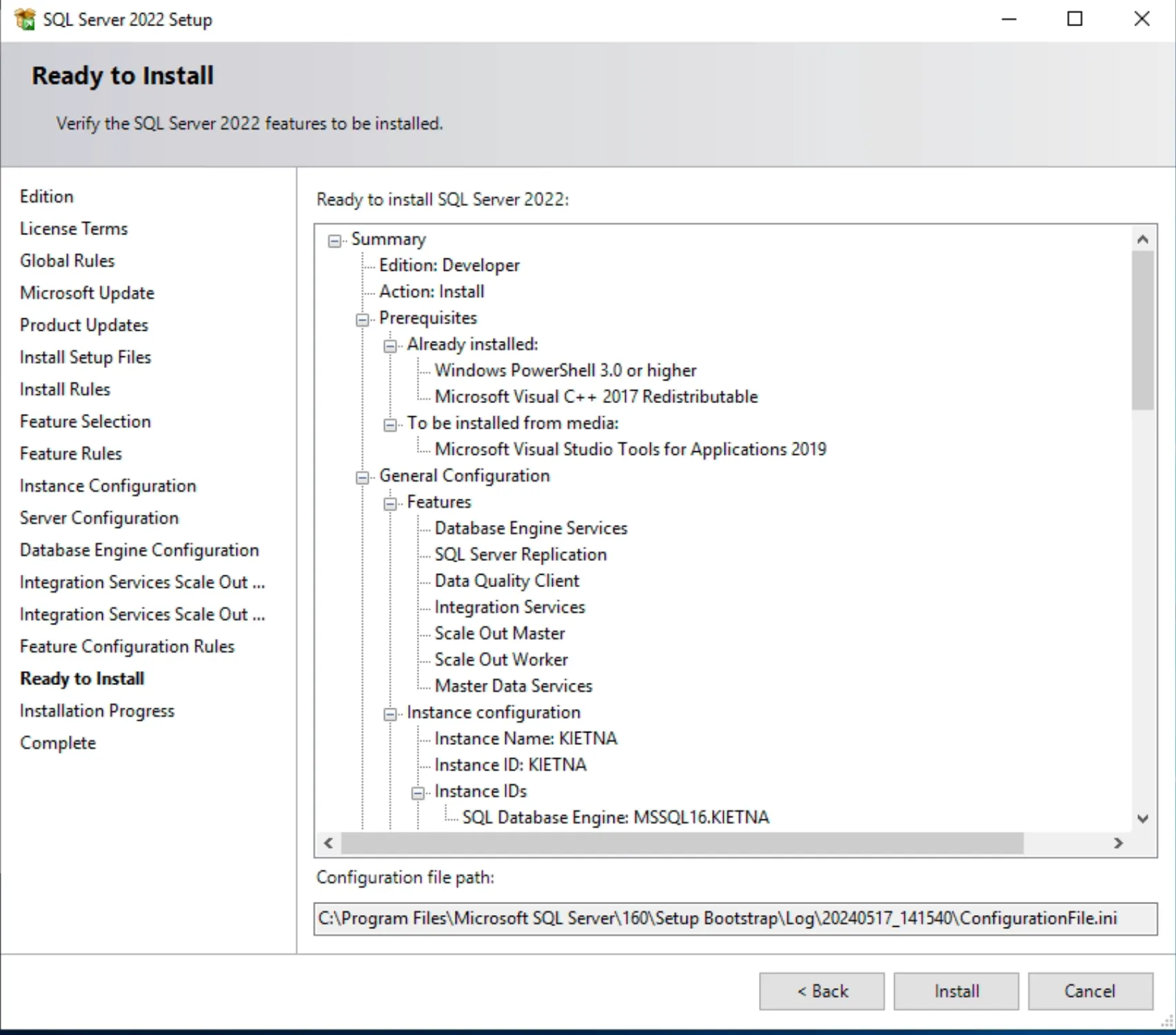
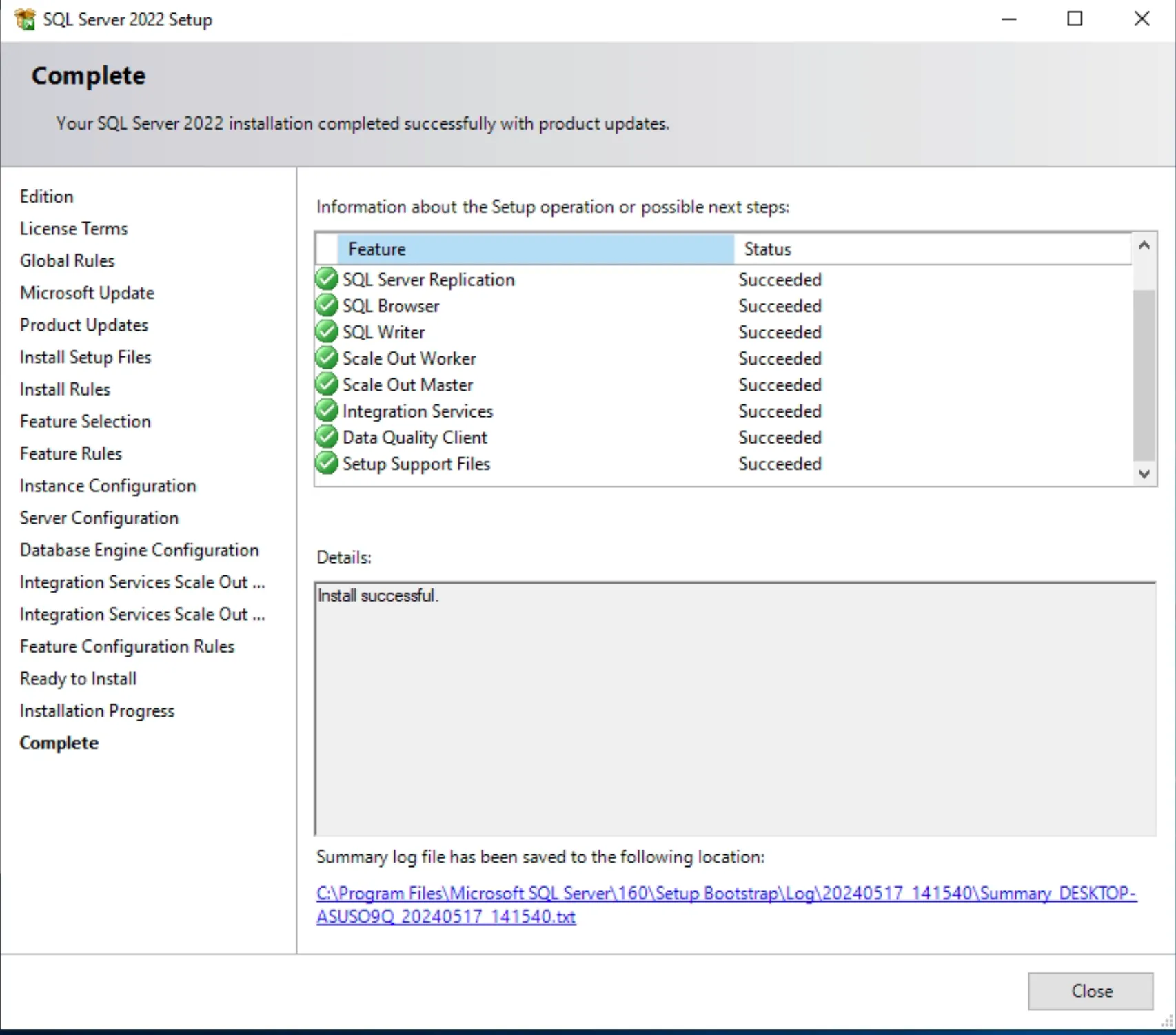
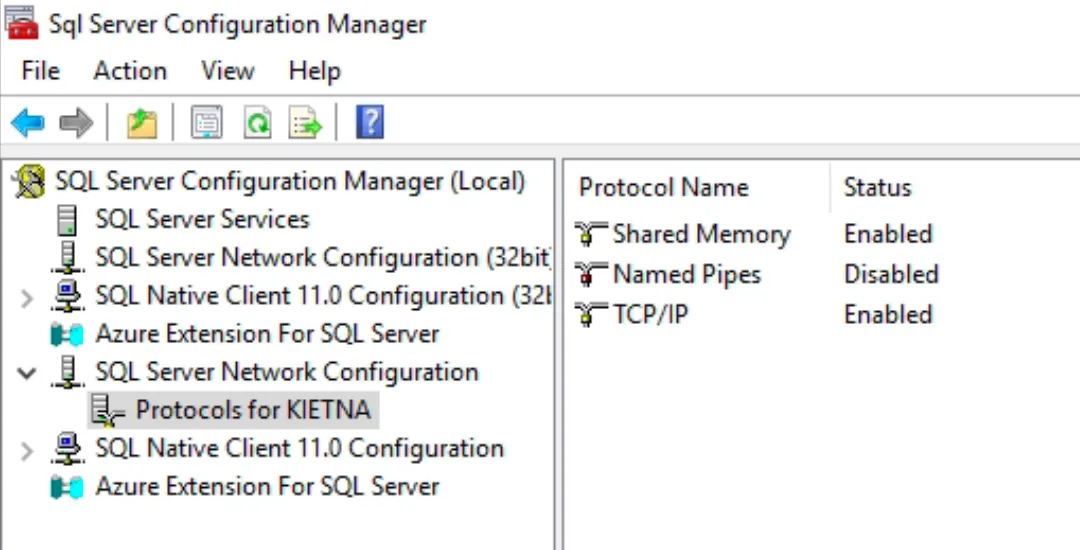
- Cấu hình cho phép truy cập qua TCP/IP
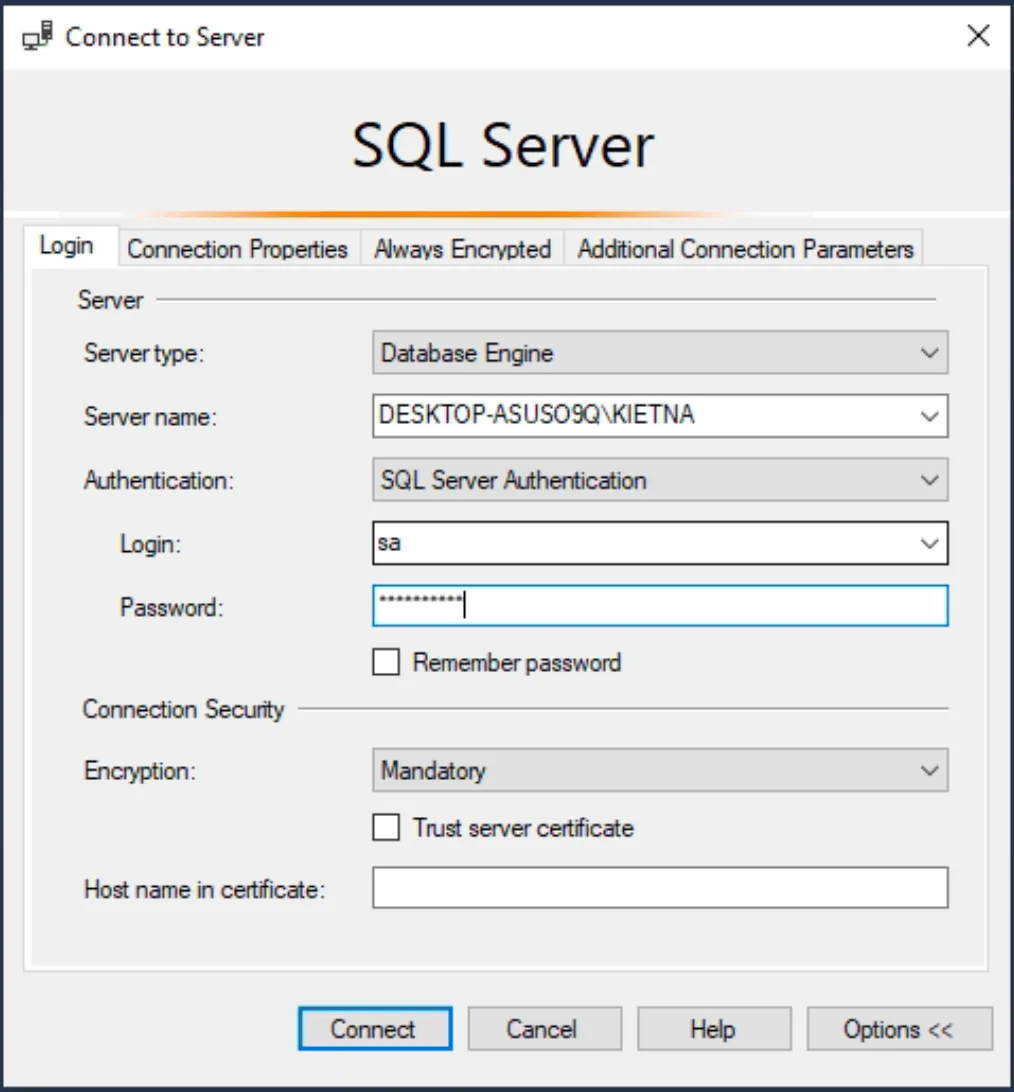
- Dùng SSMS kết nối vào DB Server
6. Triển khai SQL Server Always-on Cluster
6.1. AlwaysOn Availability Groups
- AlwaysOn Availability Groups là một giải pháp HA & DR thay thế cho Database Mirroring hoặc Log Shipping
- Mỗi một Availability Group hỗ trợ môi trường failover cho một nhóm các user databases nhất định, gọi là Availability Database
- Nhóm các Database này ở chung trong 1 instance, gọi là Replica
- Các Database trong một group có khả năng fail over cùng nhau từ 1 Repica chính, trong trường hợp cần thiết qua một Replica khác
- Luôn có một Primary Replica duy nhất và có thể có tối đa 4 secondary replica trong đó có tối đa 2 active secondary replica cho phép đọc và/hoặc thực hiện backup
- Mỗi replica phải ở trên các node khác nhau trong WSFC cluster, nghĩa là mỗi Instance phải ở trên 1 server khác nhau (Vật lí hoặc ảo)
- Một Availability group chỉ có thể fail over ở level replica (instance). Việc fail over sẽ không diễn ra ở level của database
- Tránh các vấn đề như mất data files, database bị xóa hay transaction log bị hỏng
- Các ứng dụng kết nối đến các database nằm trong 1 availability group thông qua các Availability Group Listeners. Listener đóng vai trò như một gateway để cung cấp khả năng chuyển hướng đễn các client connection đến primary replica
6.2. Các chế độ đồng bộ
- Hỗ trợ 2 chế độ đồng bộ giữa primary replica và một secondary replica
6.2.1. Asynchronous-commit mode
- Thay thế cho Log Shipping để xây dựng một giải pháp DR cho những Replica ở cách xa nhau về mặt địa lý
- Các transaction log của primary replica sẽ được gửi một cách không liên tục và không đồng bộ để commit ở secondary replica.
- Không bắt buộc dữ liệu trong replica phải giống nhau mà có thể chấp nhận một độ trễ nhất định để đồng bộ dữ liệu giữa các replica
- Không hỗ trợ Automatic Failover.
- Khi gặp sự cố, người quản trị phải tự mình failover database (Force Manual Failover) để chuyển một Secondary Replica thành Primary Replica và chấp nhận mất dữ liệu
6.2.2. Synchronous-commit mode
- Thay thế cho Database Mirroring để có thể đảm bảo toàn vẹn dữ liệu ở tối đa 3 Replica (Kể cả Primary Replica)
- Yêu cầu Primary Replica chỉ được commit transaction log sau khi transaction log đã được gửi đến và commit ở secondary replica.
- Tốc độ đồng bộ sẽ bị giảm đáng kể nếu như đường truyền không tốt, nhưng bù lại dữ liệu được đảm bảo toàn vẹn, tránh mất mát nếu gặp sự cố
- Hỗ trợ cả Automatic Failover, Planned manual Failover, đảm bảo dữ liệu được bảo toàn sau khi Failover
- AlwaysOn Availability Groups hỗ trợ tối đa 2 secondary replica có thể cấu hình synchronous-commit mode với primary replica.
6.3. Các chế độ Failover
Có ba chế độ Failover được hỗ trợ
6.3.1. Force Manual Failover (Mất dữ liệu)
- Chỉ xảy ra khi cấu hình ở chế độ đồng bộ asynchronous-commit mode
- Một lựa chọn khôi phục dữ liệu sau thảm họa (DR) trong những trường hợp secondary replica không thể đồng bộ với primary replica và khi đó phải chấp nhận mất dữ liệu
6.3.2. Planned Manual Failover (Manual Failover): (không mất dữ liệu)
- Người quản trị sẽ quyết định failover một secondary replica thành một primary replica vì một mục đích nào đó
- Manual Failover chỉ xảy ra khi secondary được cấu hình synchronous-commit mode và đã được đồng bộ synchronized với primary replica
6.3.3. Automatic Failover (Không mất dữ liệu)
- Failover tự động xảy ra giữa một synchronized secondary replica và primary khi thỏa mãn các điều kiện sau
- Chế độ đồng bộ giữa secondary replica và primary replica là synchronous-commit mode
- Cả 2 replica đều chọn chế độ failover là Automatic Failover
- Ngay trước khi failover, trạng thái của secondary replica là synchronized
- Trong WSFC phải có Quorum thỏa mãi Failover Policy
- Flexible Failover Policy là một trong những điều kiện quan trọng quy định những nguyên nhân, điều kiện để automatic failover xảy ra, bao gồm 2 yếu tố
- Health-check timeout Threshold: sử dụng sp_server_diagnostics để kiểm tra sức khỏe của primary replica. Thời gian phản hồi được chấp nhận mặc định là 30 giây, nếu lâu hơn đồng nghĩa với việc primary replica có vấn đề.
7. Triển khai Redis single
sudo dnf update
sudo dnf install epel-release -y
sudo dnf install redis -y
sudo nano /etc/redis/redis.conf
bind 127.0.0.1 192.168.10.11- Tạo User mới trong Redis
redis-cli
ACL SETUSER kietna allcommands allkeys on >123456
ACL LIST
1) "user default on nopass ~* &* +@all"
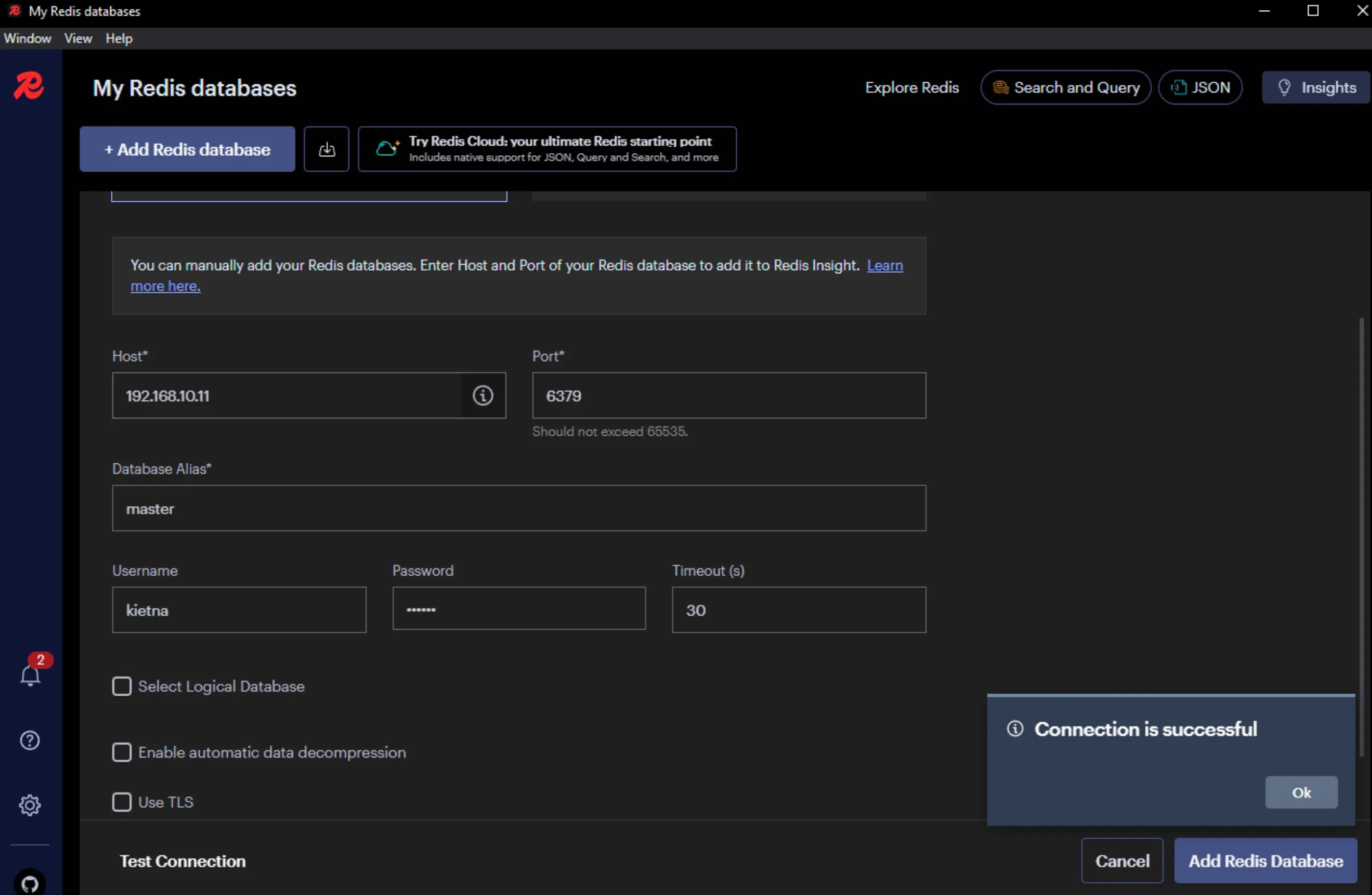
2) "user kietna on #8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92 ~* &* +@all"- Sử dụng Redis Insight để connect vào Redis Server
- Load Sample Data
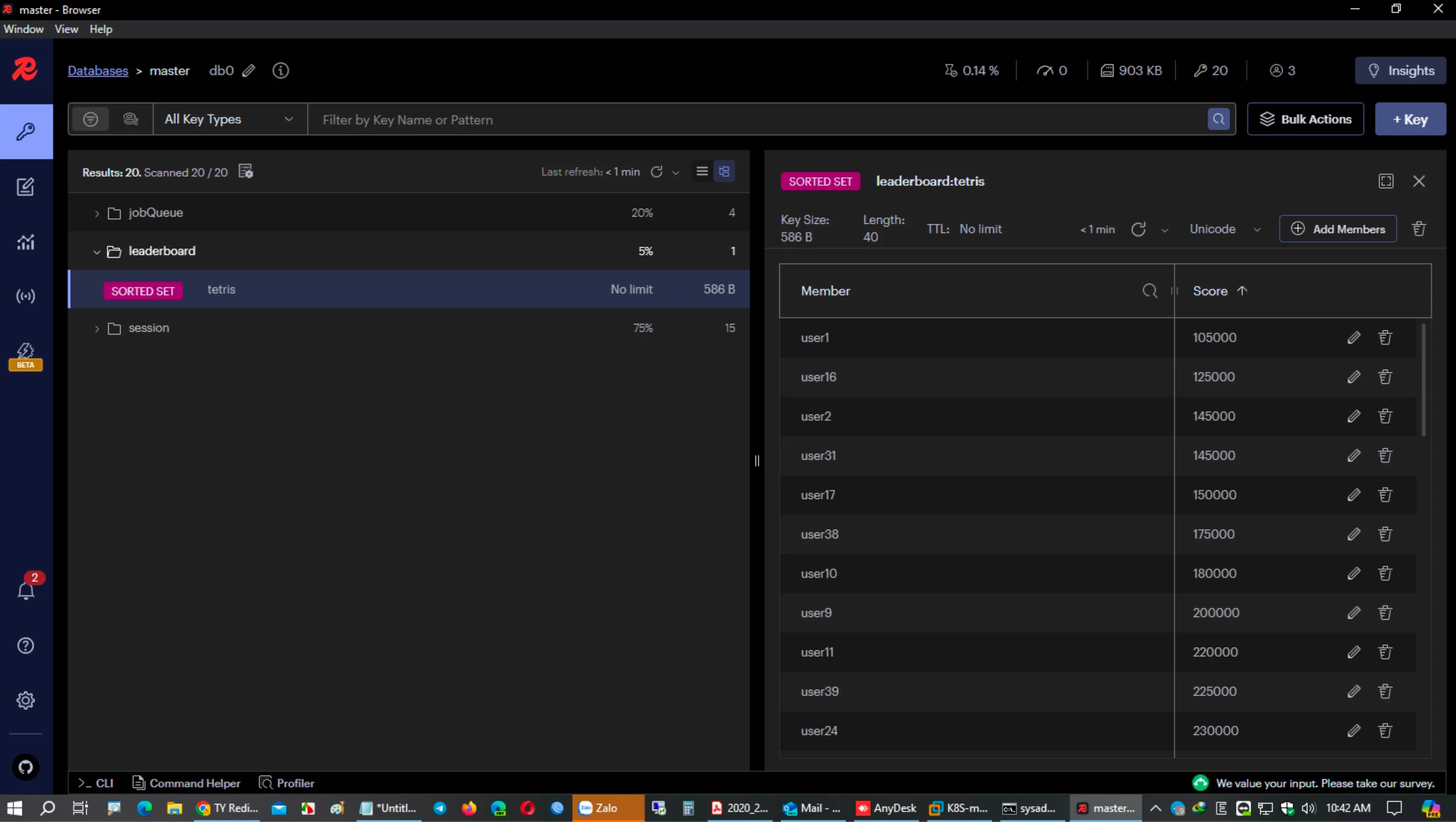
8. Triển khai Redis Cluster
- Tiến hành cài Redis lên 2 máy
- Máy Master: 192.168.10.11
- Máy Slave: 192.168.10.12
- Tại máy Master, sửa file config redis.conf như sau
sudo nano /etc/redis/redis.conf
bind 0.0.0.0
requirepass master_password
tcp-keepalive 60
maxmemory-policy noeviction
appendonly yes
appendfilename "appendonly.aof"- Tại máy Slave, sửa file config redis.conf như sau
sudo nano /etc/redis/redis.conf
bind 0.0.0.0
requirepass slave_password
slaveof ip_master 6379
masterauth master_password- Sau đó khởi chạy lại Redis Server trên 2 máy
sudo systemctl restart redis.service- Kiểm tra bằng cách kết nối vào redis-cli
- Trên máy master
[sysadmin@master1 ~]$ redis-cli
127.0.0.1:6379> AUTH default 123456
OK
127.0.0.1:6379> info replication
# Replication
**role:master
connected_slaves:1
slave0:ip=192.168.10.12,port=6379,state=online,offset=7205,lag=0
master_failover_state:no-failover**
master_replid:ce74ebbaaa93e6d6d0869b2d4ba3aac1ff1cf2bb
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7205
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:7205- Trên máy slave
[sysadmin@worker1 ~]$ redis-cli
127.0.0.1:6379> AUTH default 234567
OK
127.0.0.1:6379> info replication
# Replication
**role:slave
master_host:192.168.10.11
master_port:6379
master_link_status:up**
master_last_io_seconds_ago:4
master_sync_in_progress:0
slave_read_repl_offset:7261
slave_repl_offset:7261
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:ce74ebbaaa93e6d6d0869b2d4ba3aac1ff1cf2bb
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:7261
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:7261- Tại máy Master, tiến hành Import Sample Data
- Dễ thấy dữ liệu được đồng bộ về máy Slave
- Tại máy Master tạo một key-value mới trong bảng leaderboard
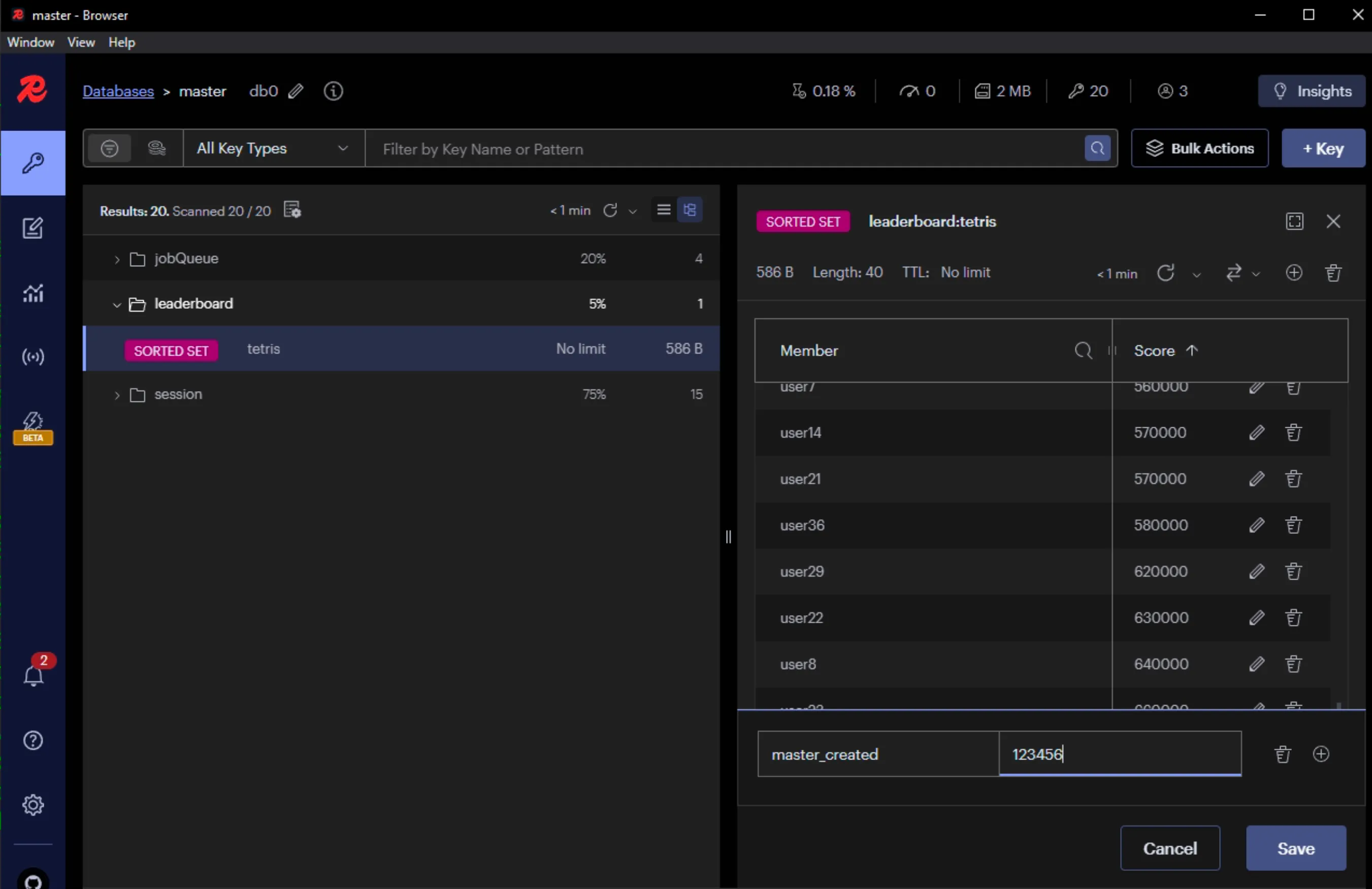
- Tại máy Slave thấy data mới được đồng bộ-
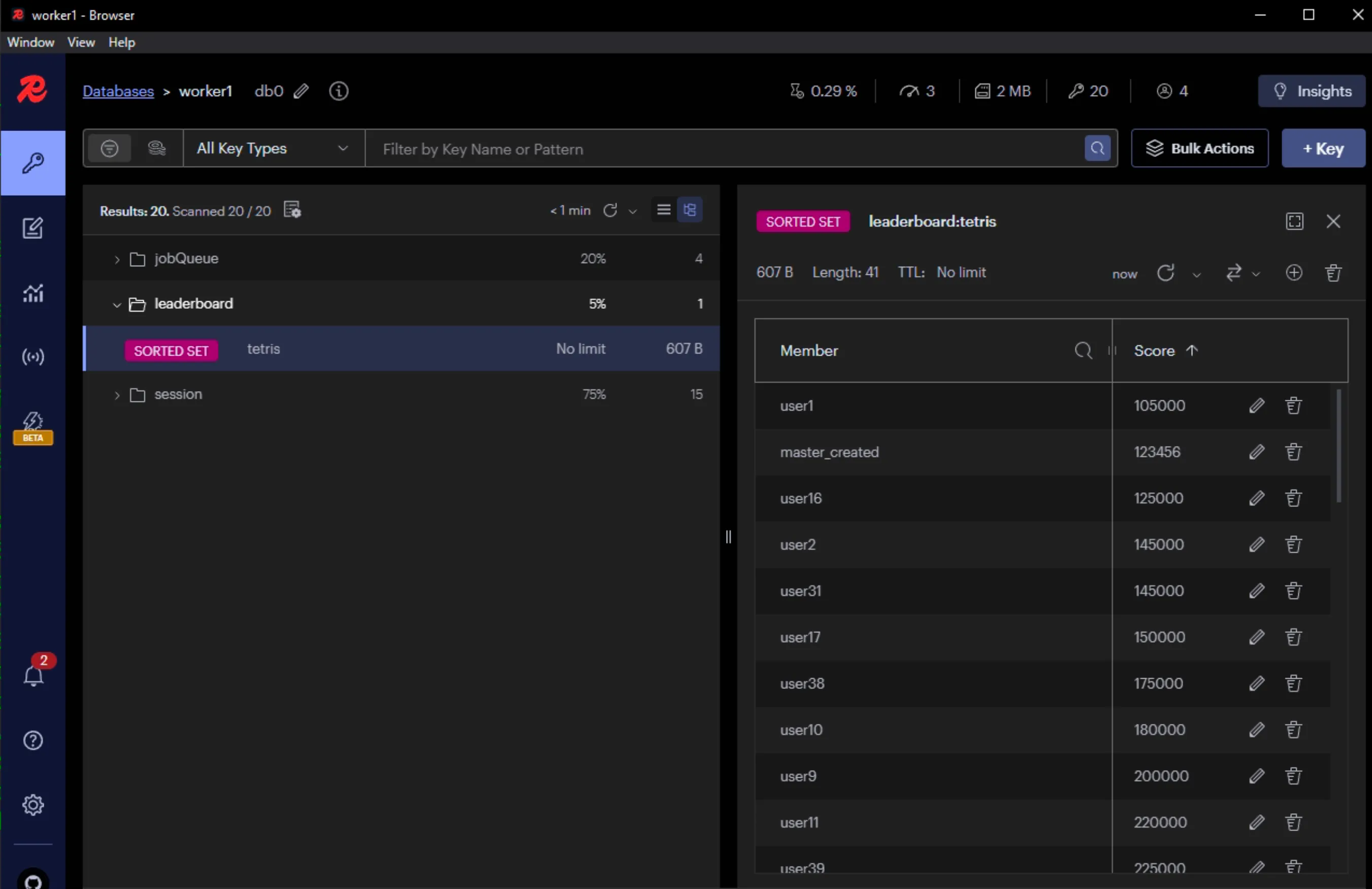
- Tại slave không thể tạo key mới vì là READ_ONLY_REPLICA
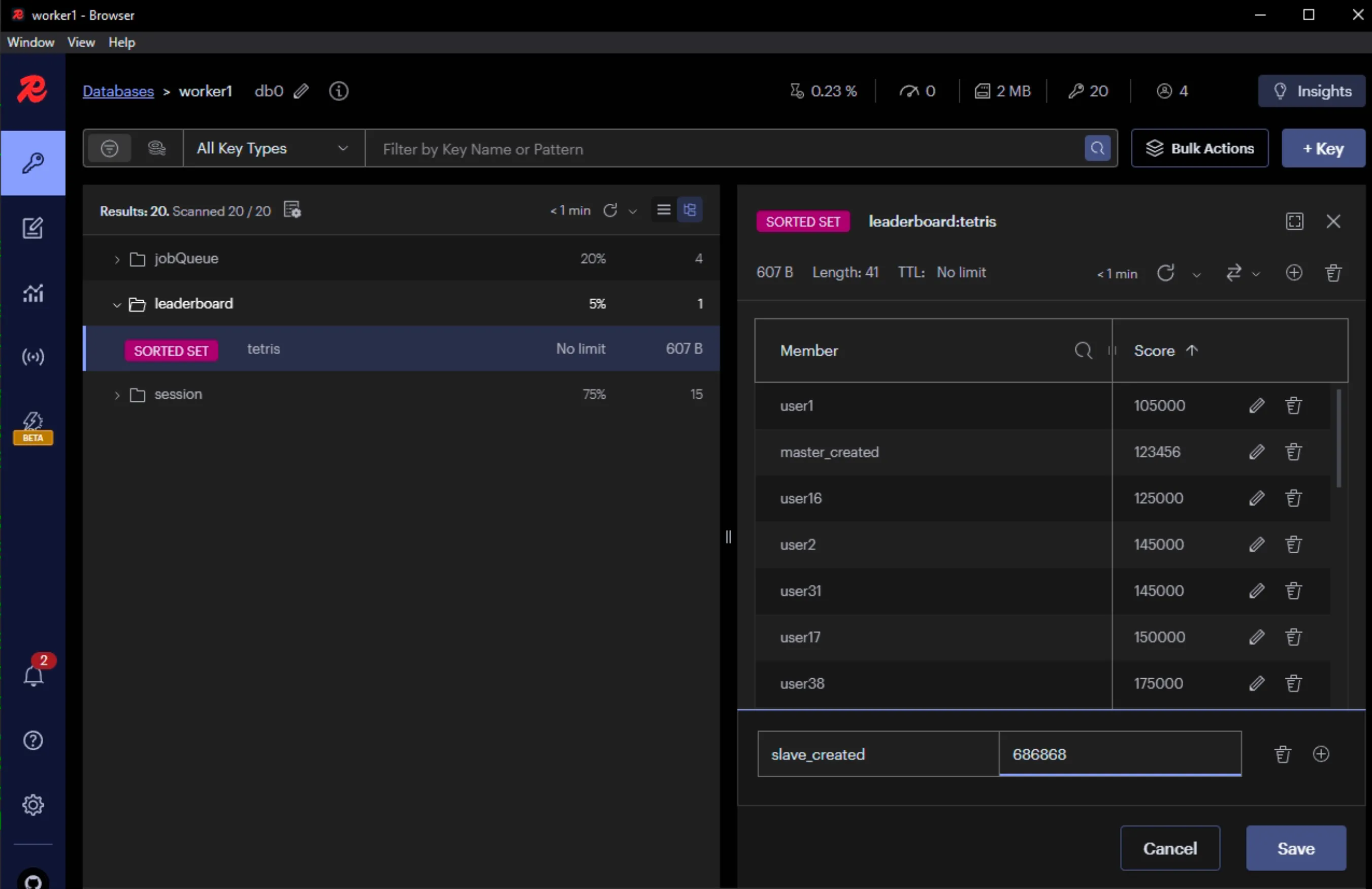
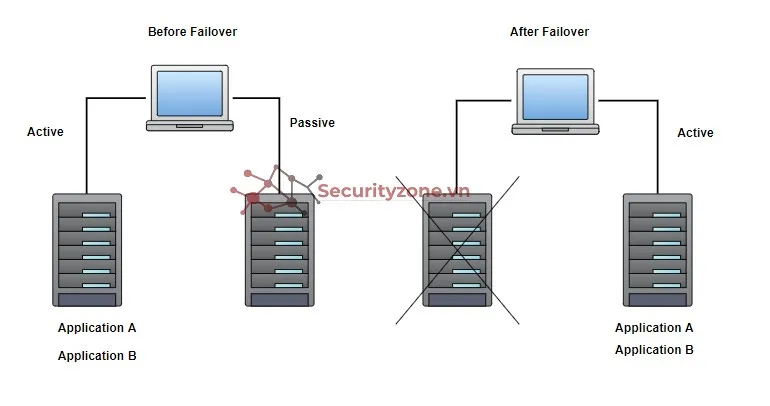
9. MySQL Active - Standby (Active/Passive)
- Cluster được tạo thành từ nhiều node tuy nhiên các node sẽ không cùng hoạt động, ví dụ trong trường hợp 2 node, node đầu tiên đã hoạt động (active) thì node thứ 2 sẽ ở chế độ chờ (standby), mục đích của cụm này là để dự phòng
- Lab
- Máy Active: 192.168.10.137
- Máy Passive: 192.168.10.138
- Cài đặt MariaDB lần lượt lên 2 máy (Như phần Single)
- Cài đặt User kietna, Password 123456@abc với toàn quyền
CREATE USER 'kietna'@'%' IDENTIFIED BY '123456@abc';
GRANT ALL PRIVILEGES ON *.* TO 'kietna'@'%' WITH GRANT OPTION;
FLUSH PRIVILEGES;- Tắt Firewall
sudo systemctl stop firewalld
sudo systemctl disable firewalld- Sửa file /etc/my.cnf
- Node 1
[mysqld]
server-id=1
log-bin=mysql-bin
pid-file = /var/lib/mysql/localhost.pid
socket = /var/lib/mysql/mysql.sock
basedir = /usr
datadir = /var/lib/mysql
tmpdir = /tmp- Node 2
[mysqld]
server-id=2
log-bin=mysql-bin
pid-file = /var/lib/mysql/localhost.pid
socket = /var/lib/mysql/mysql.sock
basedir = /usr
datadir = /var/lib/mysql
tmpdir = /tmp- Tại Node1 và Node2 , hãy cho phép cơ sở dữ liệu Node còn lại sẽ có quyền truy cập
GRANT REPLICATION SLAVE ON *.* TO 'kietna'@'%' IDENTIFIED BY '123456@abc';
FLUSH PRIVILEGES;
FLUSH TABLES WITH READ LOCK;
show master status;- Cấu hình Slave Database Node 2 đến Node 1
change master to master_host='192.168.10.137',master_user='kietna',master_password='123456@abc',master_log_file='mysql-bin.000003',master_log_pos=637;- Cấu hình Slave Database Node 1 đến Node 2
change master to master_host='192.168.10.138',master_user='kietna',master_password='123456@abc',master_log_file='mysql-bin.000001',master_log_pos=2122;- Sửa file cấu hình
nano /usr/lib/tmpfiles.d/mariadb.conf
d /run/mysql 0755 mysql mysql- Đặt hostname cho 2 node
hostnamectl set-hostname DB01
hostnamectl set-hostname DB02- Sửa file hosts
nano /etc/hosts
192.168.10.137 DB01
192.168.10.138 DB02- Cài đặt pacemaker+ corosync trên cả 2 node
sudo dnf config-manager --set-enabled highavailability
sudo yum install pacemaker pcs -y
sudo systemctl start pcsd.service
sudo systemctl enable pcsd.service- Thống nhất password cho hacluster trên cả 2 node
sudo passwd hacluster- Xác thực giữa 2 node (thực hiện trên 1 trong 2 node)
sudo pcs host auth DB01 DB02- Đặt tên cho cluster là MySQL_cluster
sudo pcs cluster setup --start MySQL_cluster DB01 DB02- Khởi động cluster (thực hiện trên 1 node)
sudo pcs cluster start --all
sudo pcs cluster enable --all- Đảm bảo Pacemaker và Corosync được khởi động cùng hệ thống (thực hiện trên 2 node)
sudo systemctl enable corosync.service
sudo systemctl enable pacemaker.service- Vô hiệu hóa STONITH & QUORUM
sudo pcs property set stonith-enabled=false
sudo pcs property set no-quorum-policy=ignore- Thiết lập Virtual IP
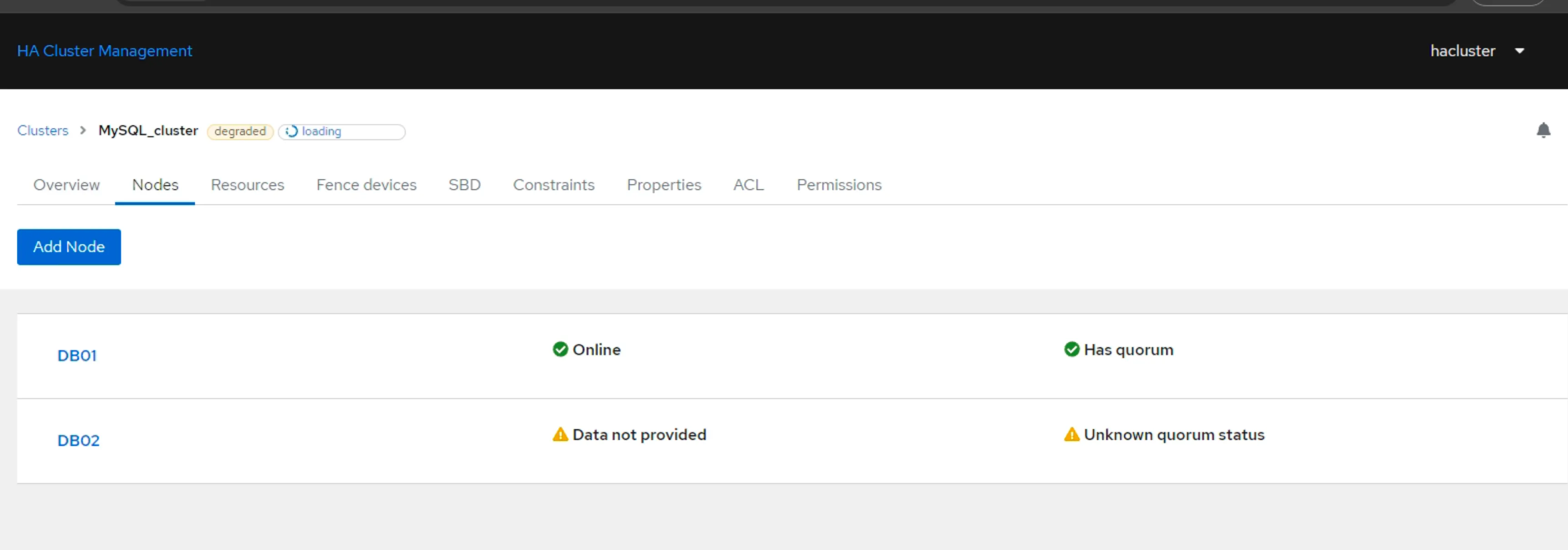
sudo pcs resource create Cluster_IP ocf:heartbeat:IPaddr2 ip=192.168.10.139 cidr_netmask=24 op monitor interval=30s- Truy cập vào trang quản trị
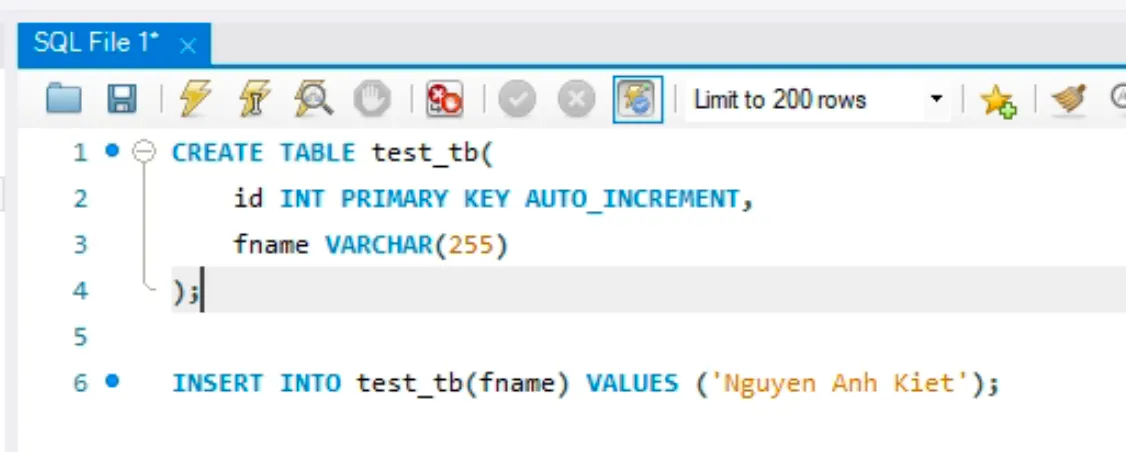
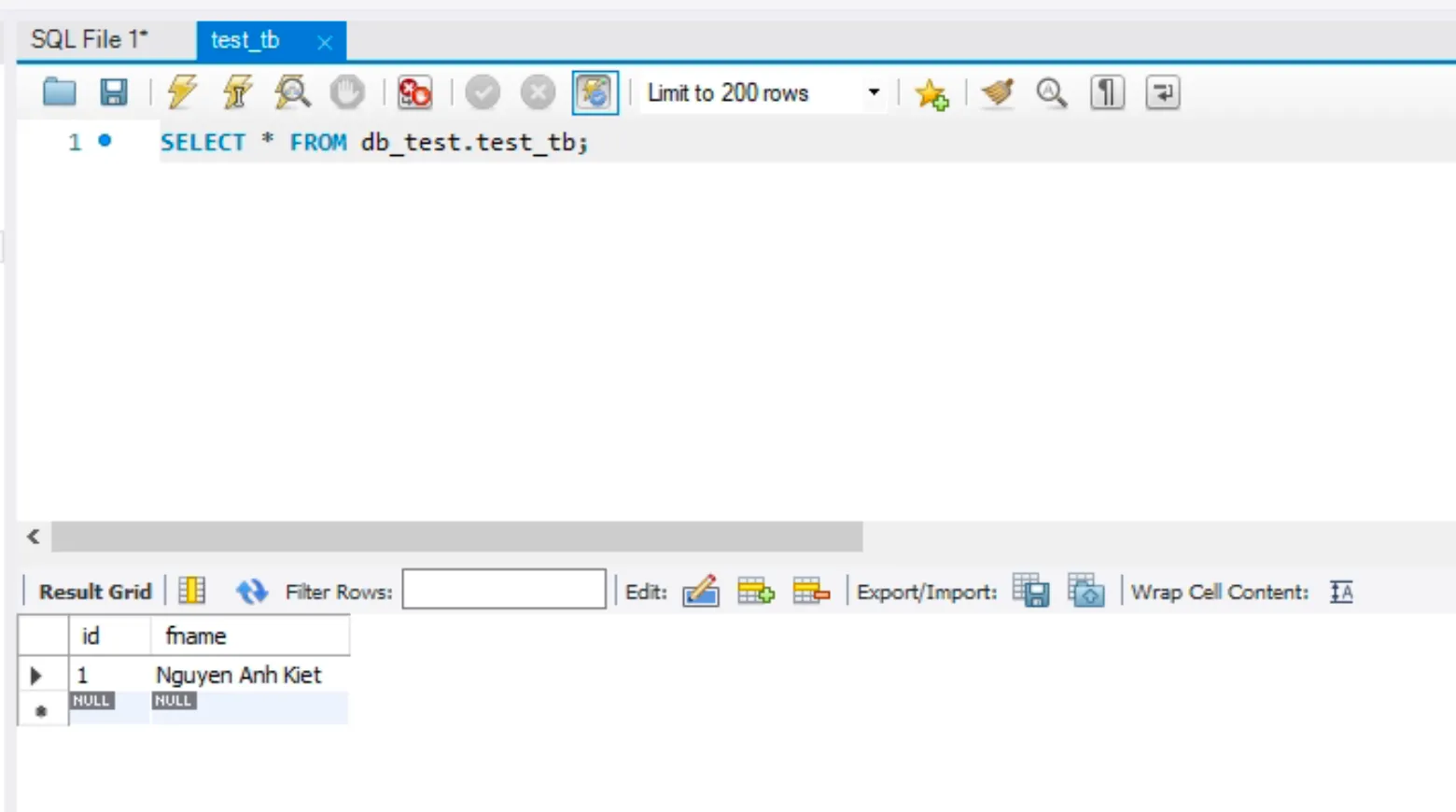
- Dùng MySQL Workbench kết nối tới Virtual IP và tạo DB + chèn 1 record vào Table
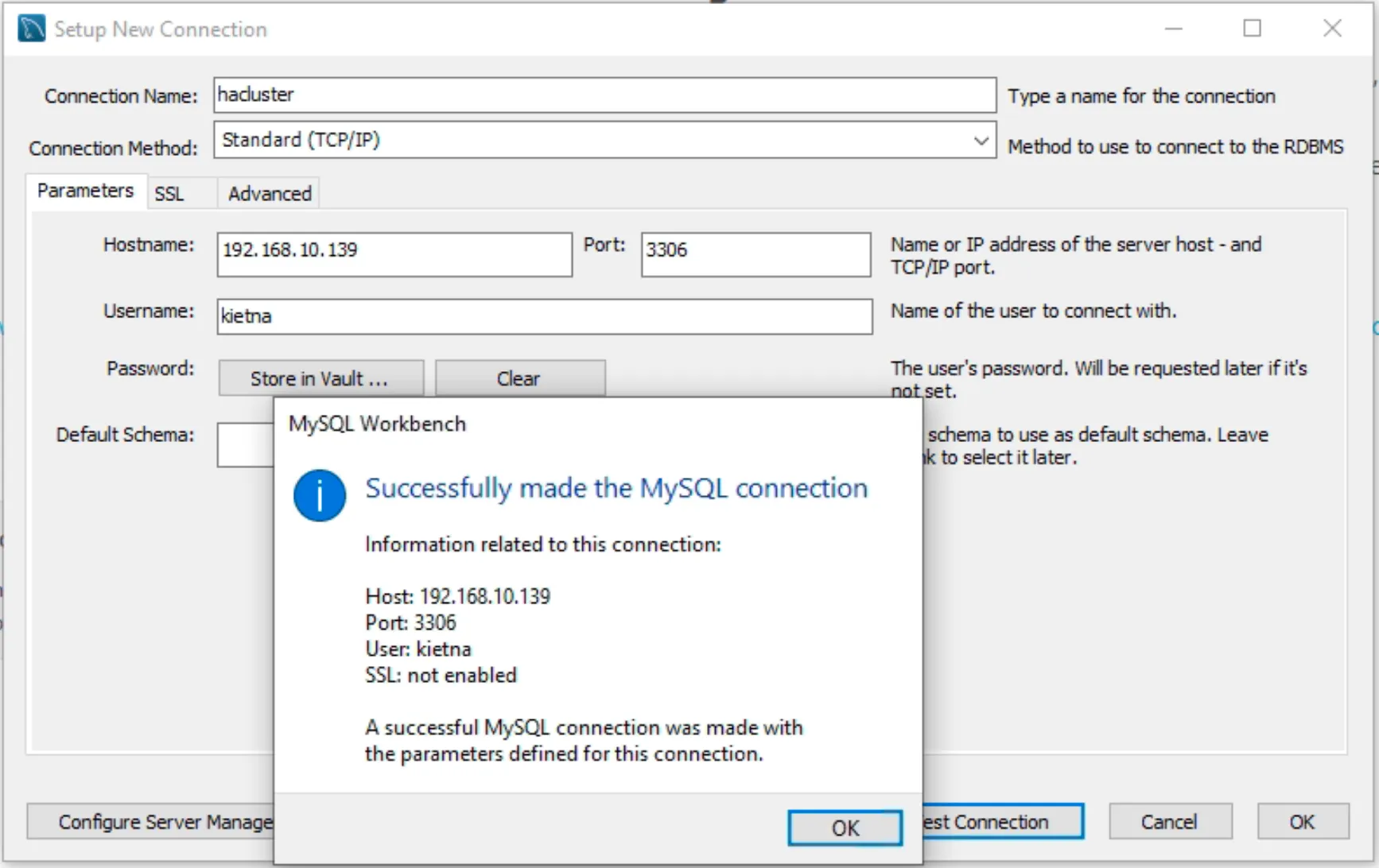
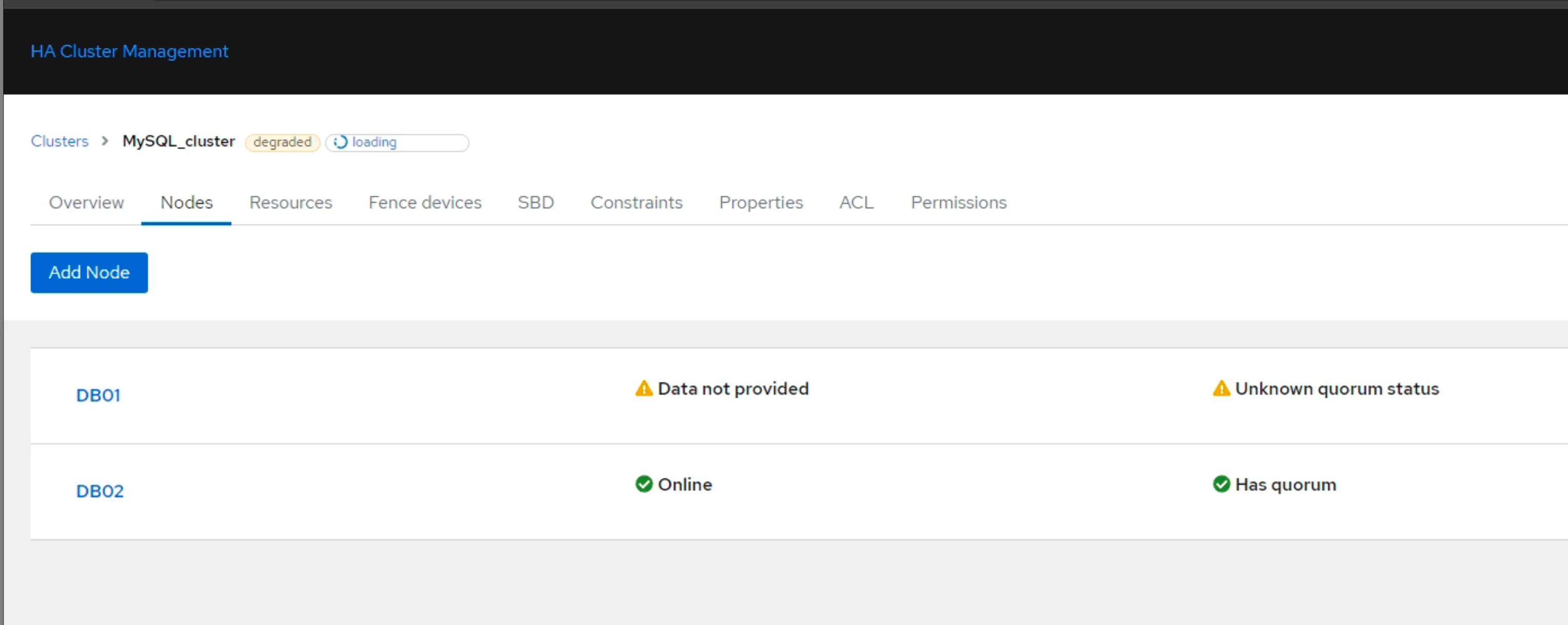
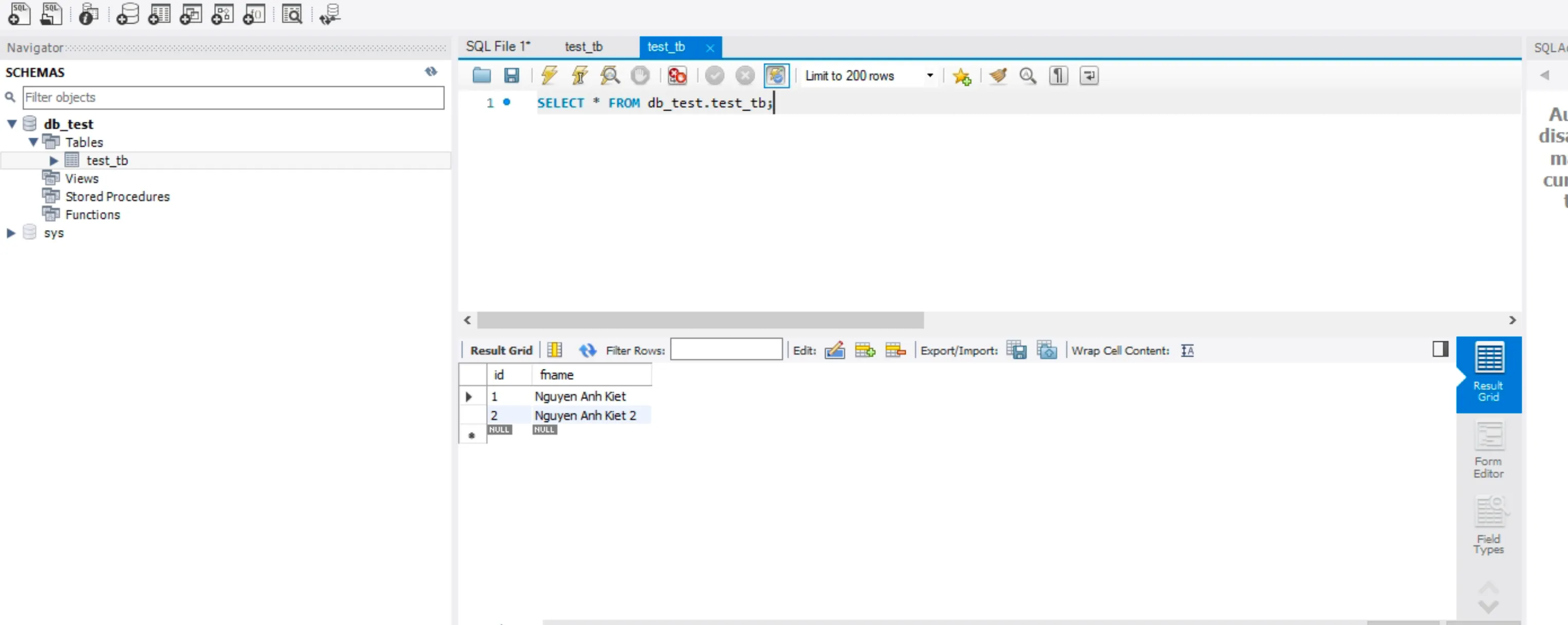
- Tắt Node 1, lúc này Node 2 sẽ trở thành Active, chèn 1 record mới vào DB
- Bật Node 1 lên, đợi data đồng bộ, tắt Node2 đi khi truy cập vào DB vẫn hiện đủ record